# jdk-8 , maven-3.6.3 node-14.15.0(是否需要自己编译前端代码调整) Gradle-4.6(是否编译Qualitis质量服务) hadoop-3.1.1,Spark-3.0.1,Hive-3.1.2,Flink-1.13.2,Sqoop-1.4.7 (Apache版本) linkis-1.1.1 DataSphereStudio-1.1.0 Schudulis-0.7.0 Qualitis-0.9.2 Visualis-1.0.0 Streamis-0.2.0 Exchangis-1.0.0 Chrome建议100以下的版本 # 系统名字 版本 场景 linkis 1.1.1 引擎编排,运行执行hive,spark,flinkSql,shell,python等,数据源统一管理等 DataSphereStudio 1.1.0 实现对任务的dag编排,实现整合其他系统的规范以及统一接入,提供基于SparkSql的服务Api Schudulis 0.7.0 任务调度,以及调度详情和重跑,并且提供基于选择时间的补漏数据 Qualitis 0.9.2 提供内置Sql的版本等功能,对常见的数据质量以及可以自定义sql,对一些不符合规则的数据进行校验并写入到对应的库中 Exchangis 1.0.0 Hive到Mysql,Mysql到Hive之间的数据交换 Streamis 0.2.0 流式开发应用中心 Visualis 1.0.0 可视化报表展示,可以分享外链接
# 从序号3之后的顺序可以自己选择进行调整.但是在部署exchangis中需要注意一点,将exchangis的sqoop引擎插件,给copy到linkis的lib下的engine插件包下
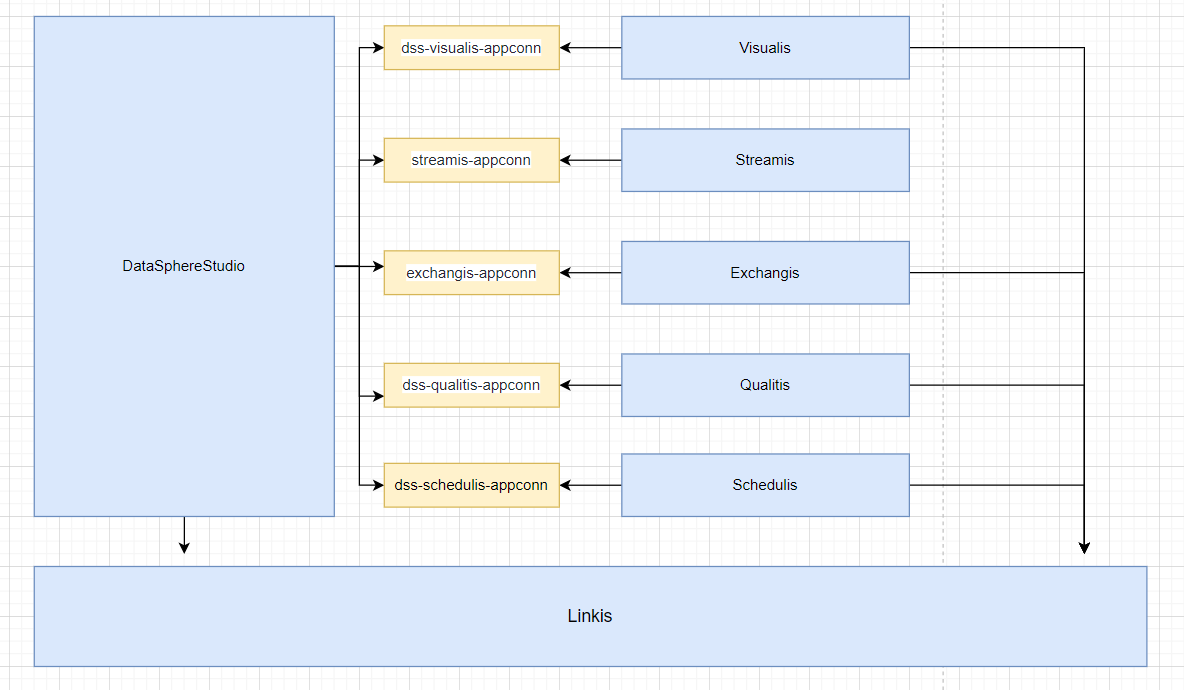
Schedulis,Qualitis,Exchangis,Streamis,Visualis等系统,都是通过各自的appconn来与dss进行整合,注意每次整合组件-appconn后,进行重启dss对应的服务模块或者重启dss
linkis DataSphereStudio Schedulis Qualitis Exchangis Streamis Visualis
如果你集成了Skywalking的话,就可以在扩拓扑图中,看到服务的状态和连接状态,如下图
# # 由于spark是采用了3.x版本的,scala也是需要升级到12版本
原项目代码地址
适配修改代码参考地址
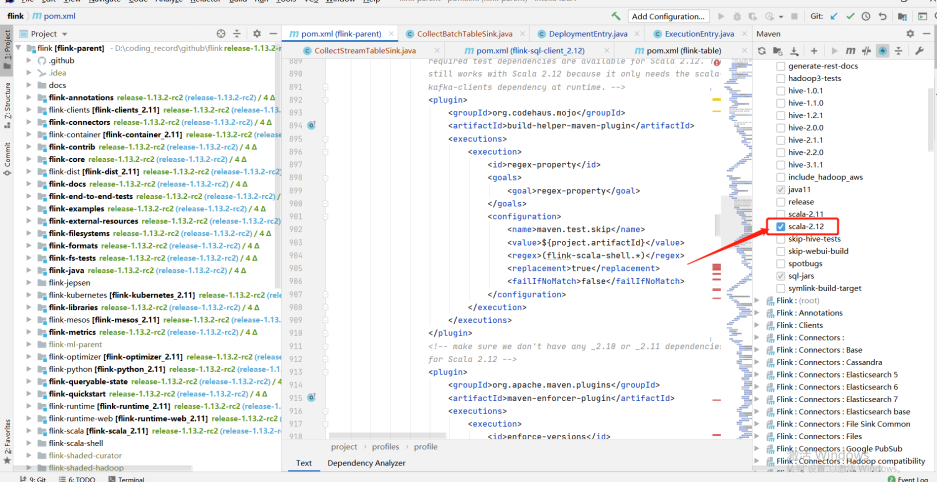
# < hadoop.version > 3.1.1 </ hadoop.version > < scala.version > 2.12.10 </ scala.version > < scala.binary.version > 2.12 </ scala.binary.version >
< dependency > < groupId > org.apache.hadoop </ groupId > < artifactId > hadoop-hdfs-client </ artifactId > < version > ${hadoop.version} </ version > Copy # < dependency > < groupId > org.apache.hadoop </ groupId > < artifactId > hadoop-hdfs-client </ artifactId > < version > ${hadoop.version} </ version > </ dependency > Copy # < hive.version > 3.1.2 </ hive.version > Copy # < spark.version > 3.0.1 </ spark.version > Copy SparkScalaExecutor 中 getField 方法需调整下代码
protected def getField(obj: Object, name: String): Object = { // val field = obj.getClass.getField(name) val field = obj.getClass.getDeclaredField("in0") field.setAccessible(true) field.get(obj) } Copy # < flink.version > 1.13.2 </ flink.version > Copy 由于flink1.12.2版本和1.13.2有些类的调整,这里目前参考社区同学给出的临时"暴力"方法: 将1.12.2部分的类给copy到1.13.2,调整scala版本到12,自己编译
涉及到flink具体的模块: flink-sql-client_${scala.binary.version}
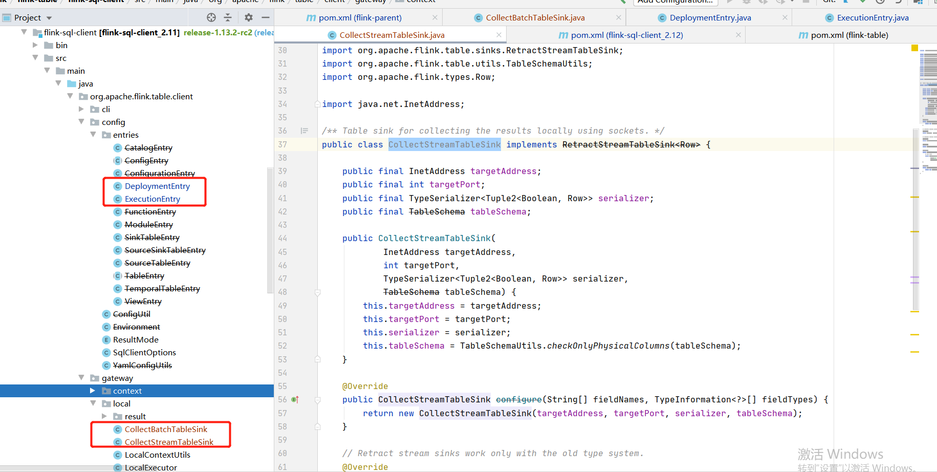
-- 注意,下列的类是从1.12.2给copy到1.13.2版本来 org.apache.flink.table.client.config.entries.DeploymentEntry org.apache.flink.table.client.config.entries.ExecutionEntry org.apache.flink.table.client.gateway.local.CollectBatchTableSink org.apache.flink.table.client.gateway.local.CollectStreamTableSink Copy
# 参考pr
如果linkis-engineplugin-python下的resource/python的python.py文件中,有import pandas as pd , 如果不想安装pandas的话,需对其进行移除
# org.apache.linkis.manager.label.conf.LabelCommonConfig
修改默认版本,便于后续的自编译调度组件使用
public static final CommonVars<String> SPARK_ENGINE_VERSION = CommonVars.apply("wds.linkis.spark.engine.version", "3.0.1");
public static final CommonVars<String> HIVE_ENGINE_VERSION = CommonVars.apply("wds.linkis.hive.engine.version", "3.1.2"); Copy # org.apache.linkis.governance.common.conf.GovernanceCommonConf
修改默认版本,便于后续的自编译调度组件使用
val SPARK_ENGINE_VERSION = CommonVars("wds.linkis.spark.engine.version", "3.0.1")
val HIVE_ENGINE_VERSION = CommonVars("wds.linkis.hive.engine.version", "3.1.2") Copy 确保以上修改和环境都有,依次执行
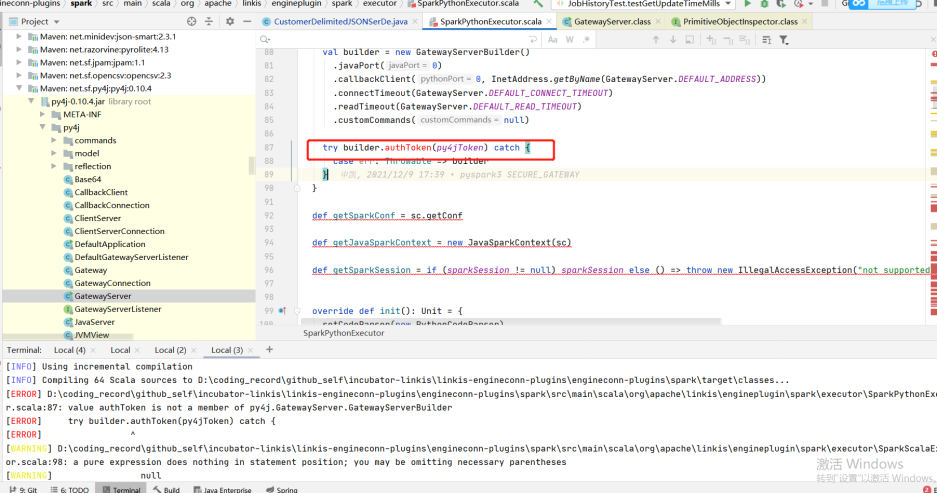
cd incubator-linkis-x.x.x mvn -N install mvn clean install -DskipTests Copy # 如果你整理进行编译的时候,出现了错误,尝试单独进入到一个模块中进行编译,看是否有错误,根据具体的错误来进行调整 比如下面举例(群友适配cdh低版本的时候,存在py4j版本不适配): 如果你遇到了这种问题,可以调整下有对应方法的版本来进行是否适配
# 原项目代码地址
适配修改代码参考地址
# 由于dss依赖了linkis,所有编译dss之前编译linkis
< scala.version > 2.12.10 </ scala.version > Copy # DolphinSchedulerTokenRestfulApi: 去掉类型的转换
responseRef.getValue("expireTime") Copy # 前端编译地址
参考pr
将如下目录从master分支的内容覆盖,或者web基于master分支去build
cd DataSphereStudio mvn -N install mvn clean install -DskipTests Copy # 原项目代码地址
适配修改代码参考地址
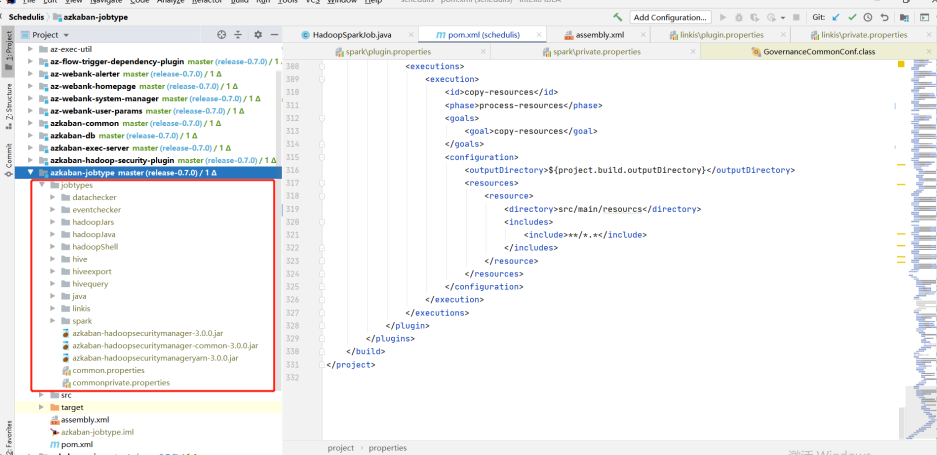
# < hadoop.version > 3.1.1 </ hadoop.version > < hive.version > 3.1.2 </ hive.version > < spark.version > 3.0.1 </ spark.version > Copy # 下载对应版本的jobtype文件(注意对应好版本): 下载地址
下载完后,将整个jobtypes放在jobtypes下
# 原项目代码地址
# release地址 下的release-0.9.1 ,解压完后放在.m2\repository\org下即可.
gradle建议使用4.6
cd Qualitis gradle clean distZip Copy 编译完后,会再qualitis下有一个qualitis-0.9.2.zip文件
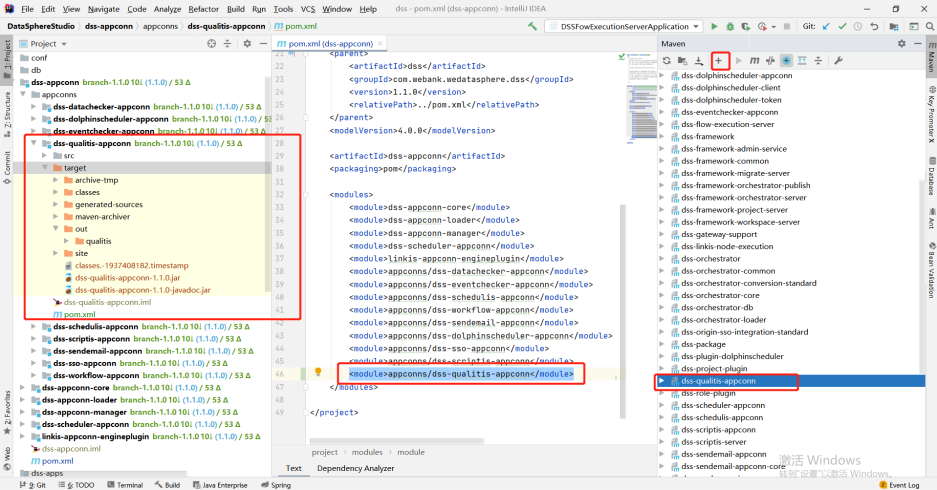
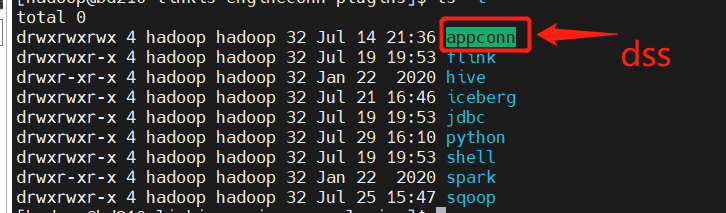
# 将appconn内从给copy到DataSphereStudio下的appconns中(创建dss-qualitis-appconn文件夹),如下图
对dss-qualitis-appconn进行编译,out下的qualitis就是dss整合qualitis的包
# 原项目代码地址
适配修改代码参考地址
# < scala.version > 2.12.10 </ scala.version > Copy # 官方编译文档
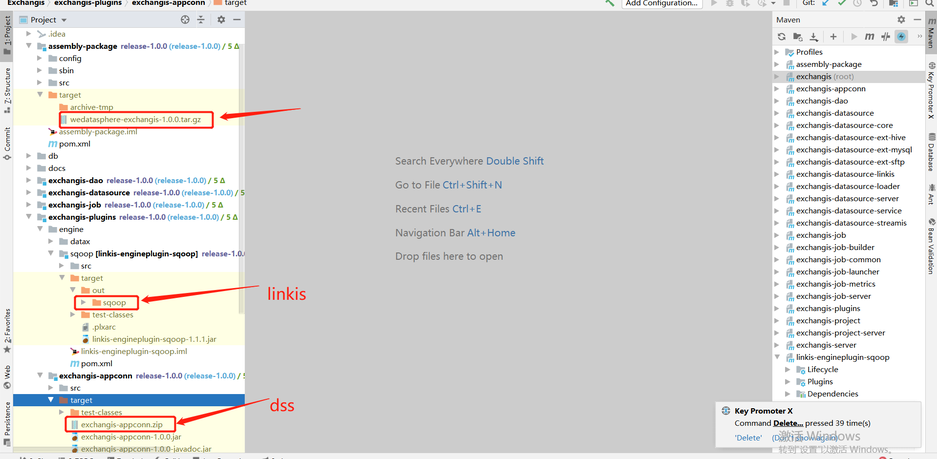
assembly-package的target包中wedatasphere-exchangis-1.0.0.tar.gz是自身的服务包
linkis-engineplugin-sqoop是需要放入linkis中(lib/linkis-engineconn-plugins)
exchangis-appconn.zip是需要放入dss中(dss-appconns)
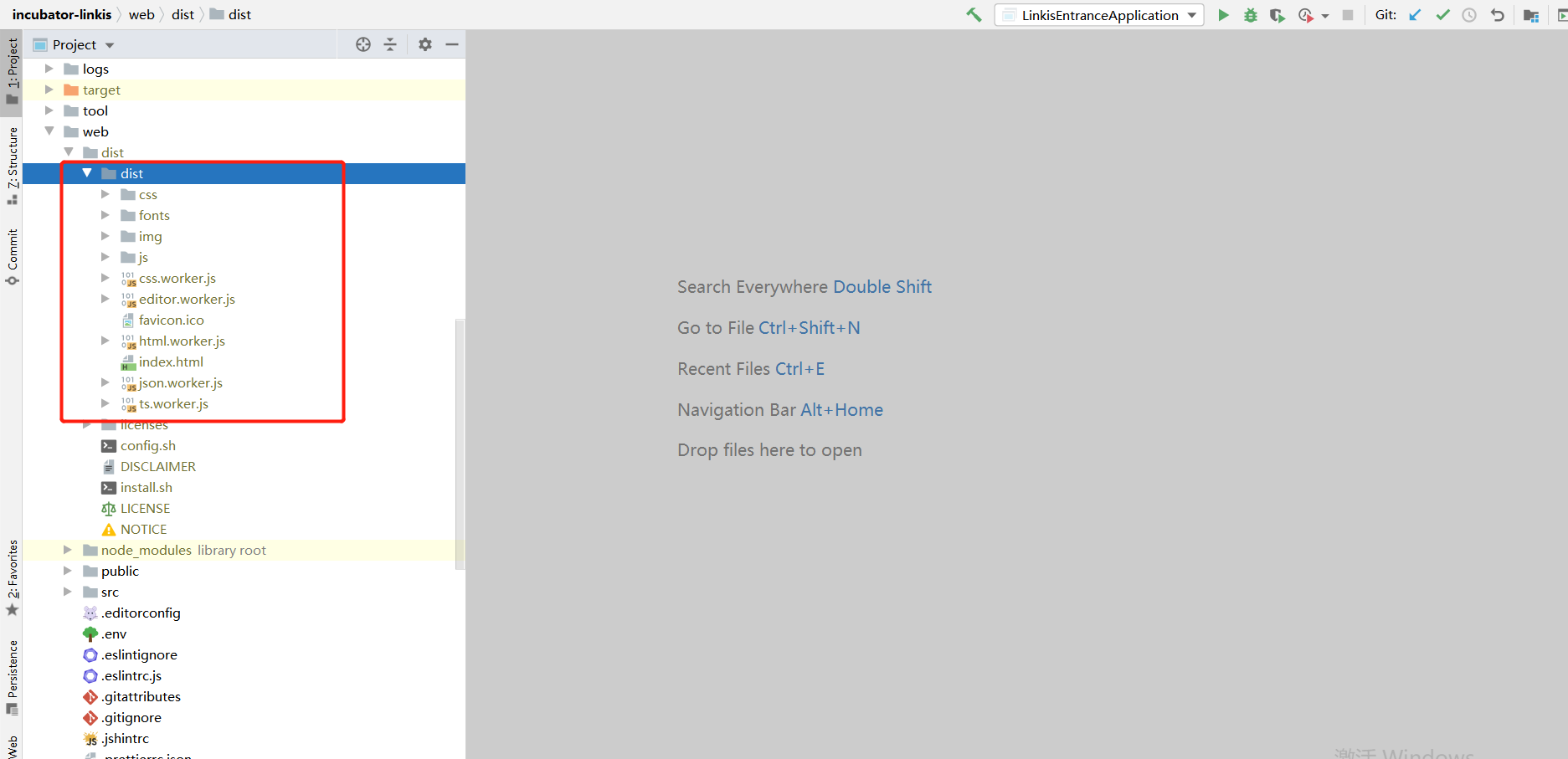
# 如果前端你是自己用nginx部署的话,需要注意是拿到dist下面dist文件夹
# 原项目代码地址
适配修改代码参考地址
# < scala.version > 2.12.10 </ scala.version > Copy 官方编译文档
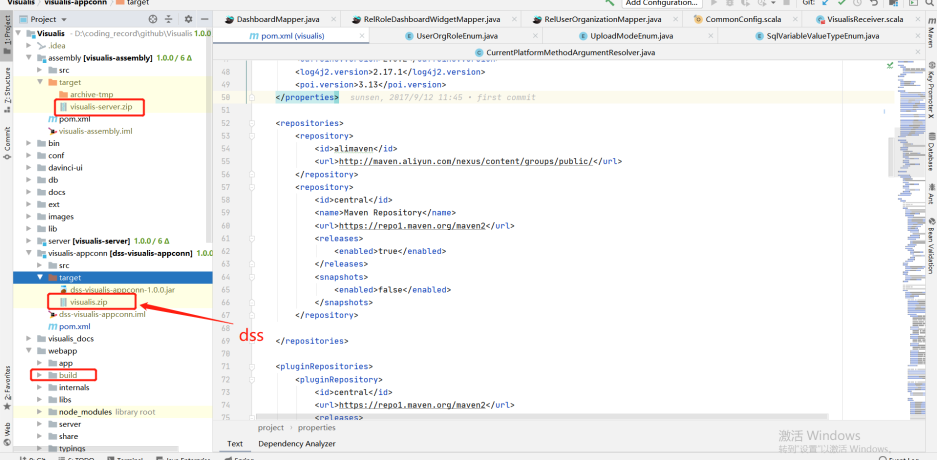
assembly下的target中visualis-server-zip是自身服务的包
visualis-appconn的target是visualis.zip是dss需要的包(dss-appconns)
build是前端打出来的包
cd Visualis mvn -N install mvn clean package -DskipTests=true Copy
# 原项目代码地址
适配修改代码参考地址
# < scala.version > 2.12.10 </ scala.version > Copy streamis-project-server的pom文件
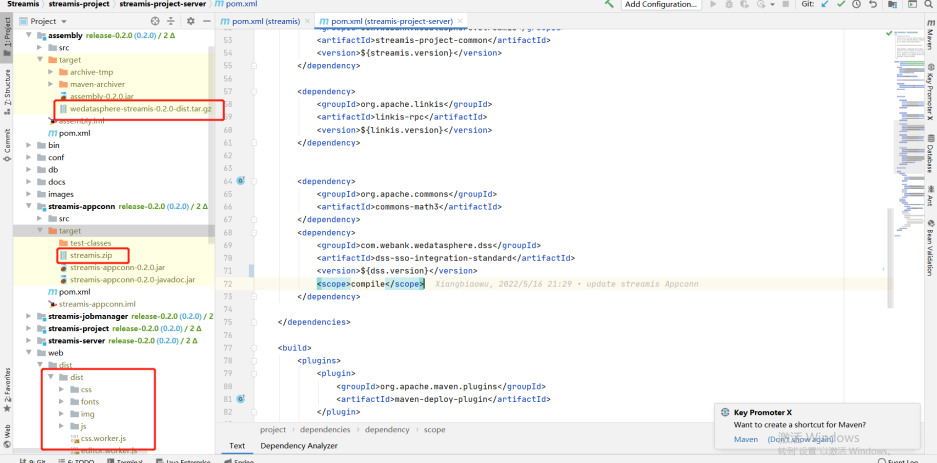
< dependency > < groupId > com.webank.wedatasphere.dss </ groupId > < artifactId > dss-sso-integration-standard </ artifactId > < version > ${dss.version} </ version > < scope > compile </ scope > </ dependency > Copy 官方编译文档
assembly下target包wedatasphere-streamis-0.2.0-dist.tar.gz是自身后端服务的包
streamis-appconn下target的streamis.zip包是dss需要的(dss-appconns)
dist下的dist是前端的包
cd ${STREAMIS_CODE_HOME} mvn -N install mvn clean install Copy
# 官方部署地址
常见错误地址
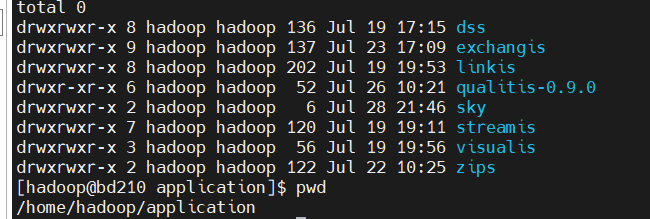
# 建议将相关的组件,部署同一个路径(比如我这里全部解压在/home/hadoop/application下)
# # db.sh中, MYSQL配置的linkis连接的地址,HIVE的元数据连接地址
linkis-env.sh
-- 保存script脚本的路径,下一次会有一个用户名字的文件夹,对应用户的脚本就存放在该文件夹中 WORKSPACE_USER_ROOT_PATH = file:///home/hadoop/logs/linkis -- 存放物料以及引擎执行的log文件 HDFS_USER_ROOT_PATH = hdfs:///tmp/linkis -- 引擎每次执行的log以及启动engineConnExec.sh相关的信息 ENGINECONN_ROOT_PATH = /home/hadoop/logs/linkis/apps -- Yarn主节点访问地址 ( Active resourcemanager ) YARN_RESTFUL_URL -- Hadoop/Hive/Spark的conf地址 HADOOP_CONF_DIR HIVE_CONF_DIR SPARK_CONF_DIR -- 指定对应的版本 SPARK_VERSION = 3.0 .1 HIVE_VERSION = 3.1 .2 -- 指定linkis安装后的路径,比如我这里就同意指定在对应组件下的路径 LINKIS_HOME = /home/hadoop/application/linkis/linkis-home Copy # 如果你使用了flink的话,可以尝试从 flink-engine.sql 导入到linkis的数据库中.
需要修改@FLINK_LABEL版本为自己对应的版本,yarn的队列默认是default.
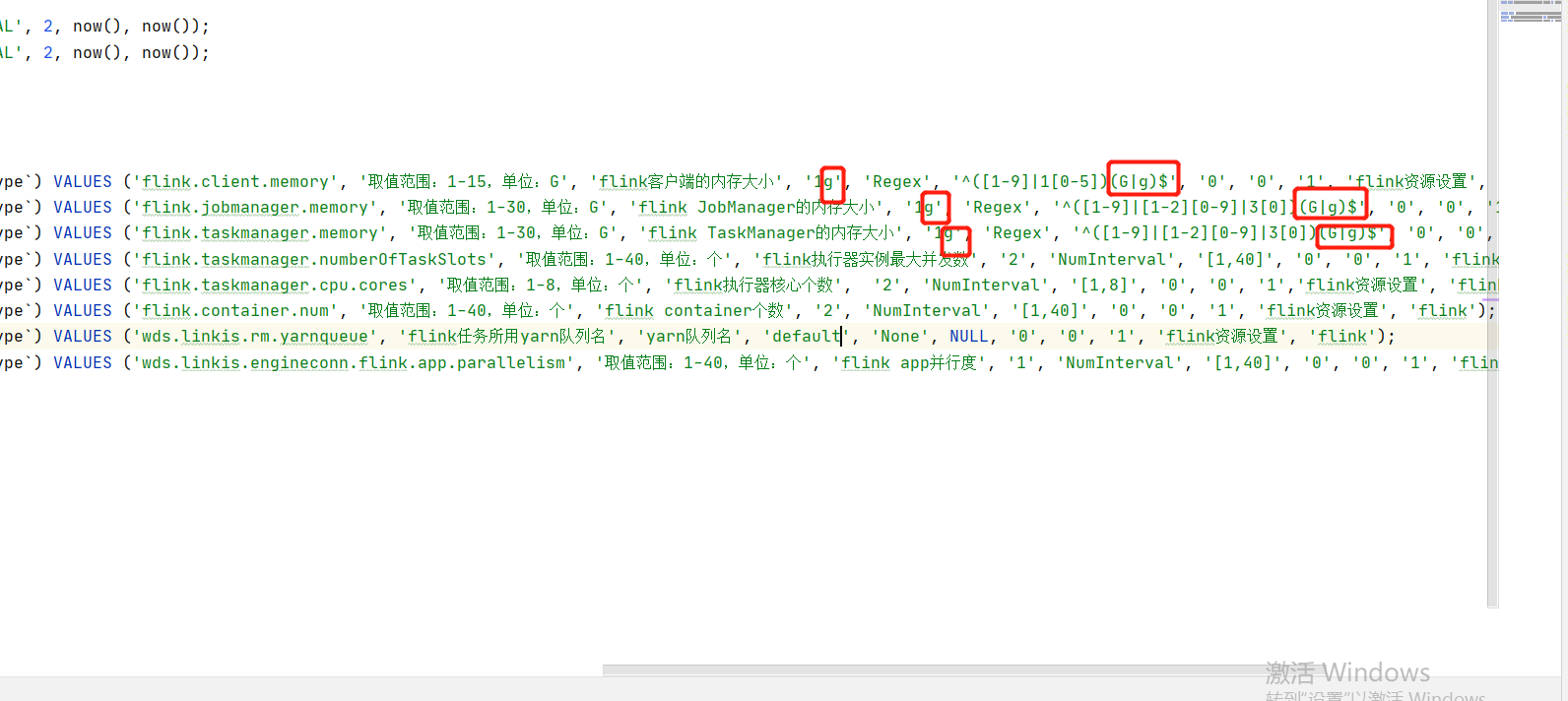
同时这个版本,如果你遇见了"1G"转换数字类型的错误,尝试去掉1g的单位以及正则校验的规则.参考如下:
# 如果你的hive使用了lzo的话,将对应的lzo的jar包给copy到hive路径下.比如下面路径:
lib/linkis-engineconn-plugins/hive/dist/v3.1.2/lib Copy # Mysql的驱动包一定要copy到/lib/linkis-commons/public-module/和/lib/linkis-spring-cloud-services/linkis-mg-gateway/ 初始化密码在conf/linkis-mg-gateway.properties中的wds.linkis.admin.password ps-cs 在启动脚本中,有可能存在存在失败的情况,如果有的话,使用 sh linkis-daemon.sh ps-cs , 对其进行单独启动 目前日志是有时间备份的话,有时候之前的错误日志找不到的话,可能是备份到对应日期的文件夹里去了 目前lib/linkis-engineconn-plugins是默认只有spark/shell/python/hive,如果你想要appconn,flink,sqoop就分别去dss中,linkis和exchangis中获取 配置文件版本检查 linkis.properties中,flink看有没有使用 wds.linkis.spark.engine.version = 3.0 .1 wds.linkis.hive.engine.version = 3.1 .2 wds.linkis.flink.engine.version = 1.13 .2 Copy
# 版本不兼容,如果你遇到了下面这种错误的话,是scala版本是否没有完全保持一致,检查后再编译一下即可.
yarn配置Active节点地址,如果是配置了Standby地址的话,就会出现如下的错误
# 官方安装文档
# db.sh: 配置dss的数据库
config.sh
-- dss的安装路径,比如我这里就定义在dss下的文件夹中 DSS_INSTALL_HOME = /home/hadoop/application/dss/dss Copy # dss.properties
# 主要检查spark/hive等版本有,如果没有,就追加上 wds.linkis.spark.engine.version=3.0.1 wds.linkis.hive.engine.version=3.1.2 wds.linkis.flink.engine.version=1.13.2 Copy dss-flow-execution-server.properties
# 主要检查spark/hive等版本有,如果没有,就追加上 wds.linkis.spark.engine.version=3.0.1 wds.linkis.hive.engine.version=3.1.2 wds.linkis.flink.engine.version=1.13.2 Copy 如果调度是想使用dolphinscheduler的话,请参数这个pr添加对应的spark/hive版本
参考pr
# exchangis,qualitis,streamis,visualis 都分别要从 Exchangis , Qualitis , Streamis, Visualis 的项目去获取
# 由于dss我们整合了schedulis,qualitis,exchangis等组件,所有创建一个项目会同步调用这些组件的接口创建,所以确保dss_appconn_instance中的配置路径都是正确的,可以访问的 chrome浏览器建议内核使用10版本一下的,否则会出现你可以单独Scdulis,Qaulitis等组件,但是却无法通过dss登录成功问题 hostname和ip,如果是使用ip访问的话,执行appconn-install.sh安装的时候,也确保是ip. 否则会出现访问其他组件的时候,会提示没有登录或者没有权限
# 官方部署文档
# azkaban.properties
# azkaban.jobtype.plugin.dir和executor.global.properties这里最好改成绝对路径 # Azkaban JobTypes Plugins azkaban.jobtype.plugin.dir=/home/hadoop/application/schedulis/apps/schedulis_0.7.0_exec/plugins/jobtypes
# Loader for projects executor.global.properties=/home/hadoop/application/schedulis/apps/schedulis_0.7.0_exec/conf/global.properties
# 引擎的版本 wds.linkis.spark.engine.version=3.0.1 wds.linkis.hive.engine.version=3.1.2 wds.linkis.flink.engine.version=1.13.2 Copy # plugins/viewer/system/conf: 这里需要配置数据库连接地址,与schedulis保持一致
azkaban.properties: 用户参数和系统管理的配置
viewer.plugins=system viewer.plugin.dir=/home/hadoop/application/schedulis/apps/schedulis_0.7.0_web/plugins/viewer Copy # 如果出现资源或者web界面出现没有css等静态文件的话,将相关的路径修改为绝对路径
如果出现配置文件加载不到的问题,也可以将路径修改为绝对路径
比如:
### web模块中 web.resource.dir=/home/hadoop/application/schedulis/apps/schedulis_0.7.0_web/web/ viewer.plugin.dir=/home/hadoop/application/schedulis/apps/schedulis_0.7.0_web/plugins/viewer
### exec模块中 azkaban.jobtype.plugin.dir=/home/hadoop/application/schedulis/apps/schedulis_0.7.0_exec/plugins/jobtypes executor.global.properties=/home/hadoop/application/schedulis/apps/schedulis_0.7.0_exec/conf/global.properties Copy # 官方部署文档
# application-dev.yml
# 这里配置正确的spark版本 spark: application: name: IDE reparation: 50 engine: name: spark version: 3.0.1 Copy # 官方部署文档
# 如果点击数据源出现没有发布的错误的话,可以尝试将linkis_ps_dm_datasource的published_version_id值修改为1(如果是null的话)
# 官方部署文档
# 如果出现预览视图一致出不来的话,请检查bin/phantomjs该文件是否完整上传.
如果能看到如下结果的话,说明是上传是完整的
# 官方部署文档
# qualitis,exchangis,streamis,visualis是分别要从各种的模块中编译好,copy到dss下的dss-appconns中,然后执行bin下的appconn-install.sh来为各自的组件进行安装
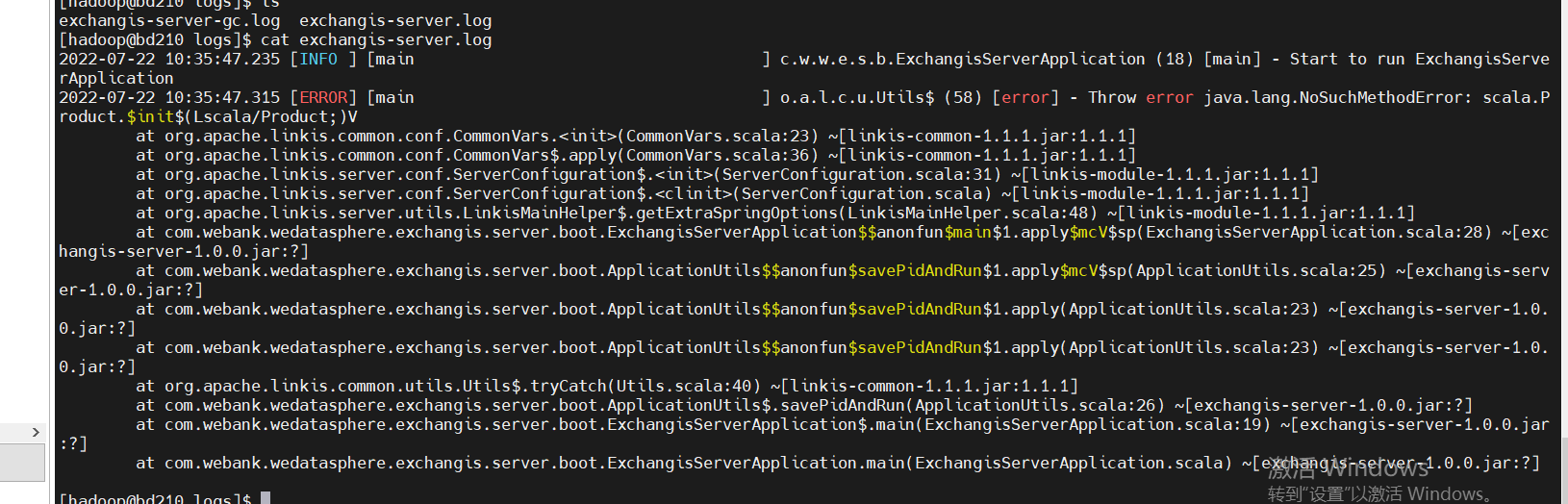
如果你在整合的时候,如果到一些如下的Sql脚本错误的话,请检测错误的Sql周边是否有注释,如果有的话,删掉注释再重新appconn-install一遍尝试
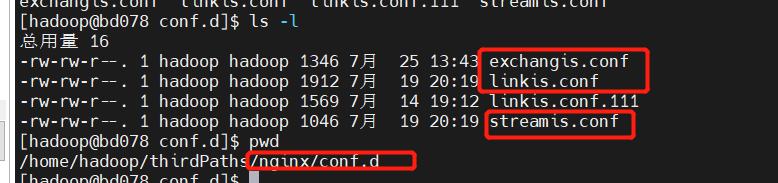
qualitis 172.21.129.78 8090 Copy # linkis.conf: dss/linkis/visualis 前端
exchangis.conf: exchangis前端
streamis.conf: streamis前端
Schedulis和Qualitis是分别在自己项目中.
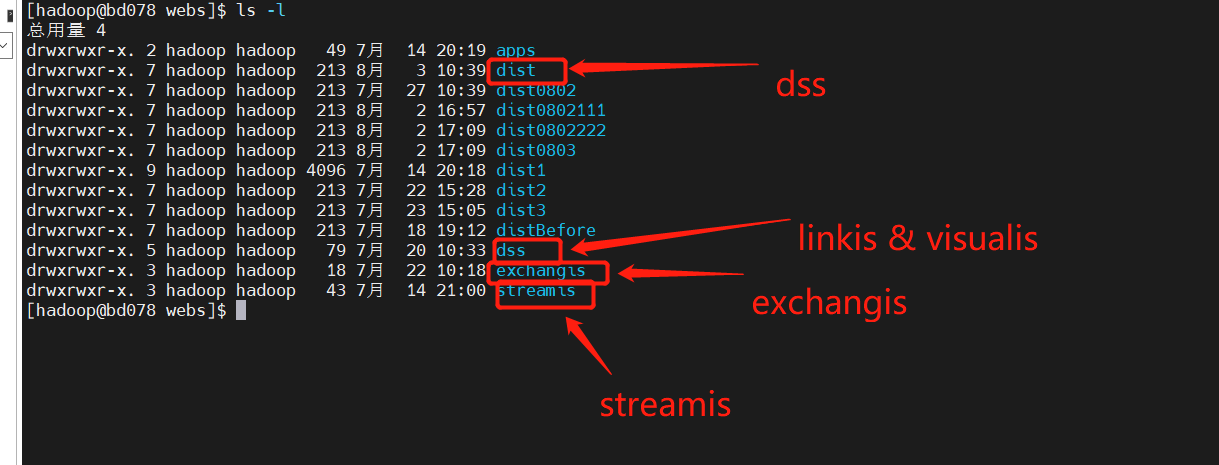
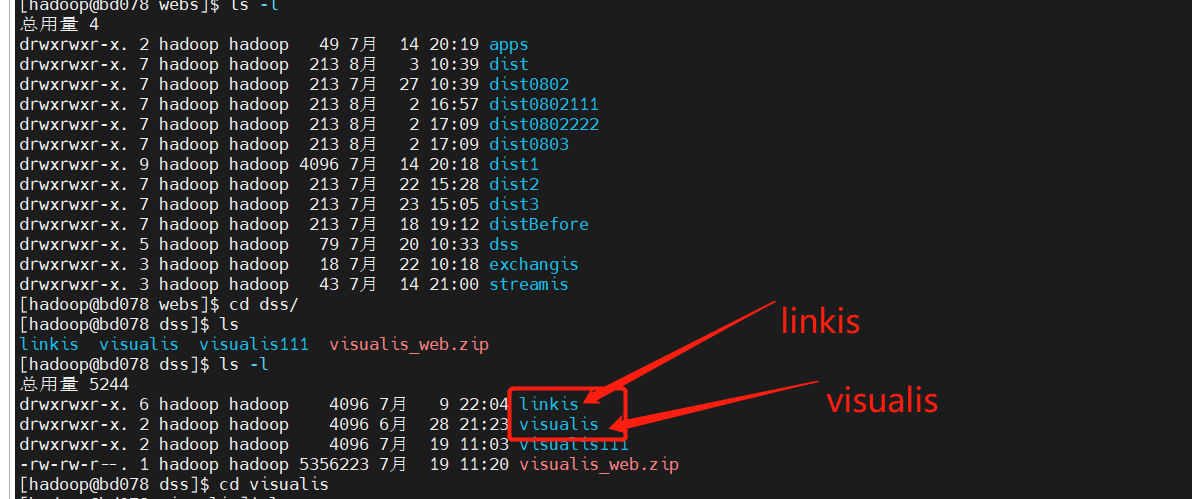
linkis/visualis需要将前端打包出来的dist或者build在这里修改为对应组件的名字
# server { listen 8089;# 访问端口 server_name localhost; #charset koi8-r; #access_log /var/log/nginx/host.access.log main;
location /dss/visualis { # 修改为自己的前端路径 root /home/hadoop/application/webs; # 静态文件目录 autoindex on; }
location /dss/linkis { # 修改为自己的前端路径 root /home/hadoop/application/webs; # linkis管理台的静态文件目录 autoindex on; }
location / { # 修改为自己的前端路径 root /home/hadoop/application/webs/dist; # 静态文件目录 #root /home/hadoop/dss/web/dss/linkis; index index.html index.html; }
location /ws { proxy_pass http://172.21.129.210:9001;#后端Linkis的地址 proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection upgrade; }
location /api { proxy_pass http://172.21.129.210:9001; #后端Linkis的地址 proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header x_real_ipP $remote_addr; proxy_set_header remote_addr $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_http_version 1.1; proxy_connect_timeout 4s; proxy_read_timeout 600s; proxy_send_timeout 12s; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection upgrade; }
#error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }
Copy # server { listen 9800; # 访问端口 如果该端口被占用,则需要修改 server_name localhost; #charset koi8-r; #access_log /var/log/nginx/host.access.log main; location / { # 修改为自己路径 root /home/hadoop/application/webs/exchangis/dist/dist; # Exchangis 前端部署目录 autoindex on; }
location /api { proxy_pass http://172.21.129.210:9001; # 后端Linkis的地址,需要修改 proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header x_real_ipP $remote_addr; proxy_set_header remote_addr $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_http_version 1.1; proxy_connect_timeout 4s; proxy_read_timeout 600s; proxy_send_timeout 12s; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection upgrade; }
#error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }
Copy # server { listen 9088;# 访问端口 如果该端口被占用,则需要修改 server_name localhost; location / { # 修改为自己的路径 root /home/hadoop/application/webs/streamis/dist/dist; # 请修改成Streamis前端的静态文件目录 index index.html index.html; } location /api { proxy_pass http://172.21.129.210:9001; #后端Linkis的地址,请修改成Linkis网关的ip和端口 proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header x_real_ipP $remote_addr; proxy_set_header remote_addr $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_http_version 1.1; proxy_connect_timeout 4s; proxy_read_timeout 600s; proxy_send_timeout 12s; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection upgrade; }
#error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } } Copy 
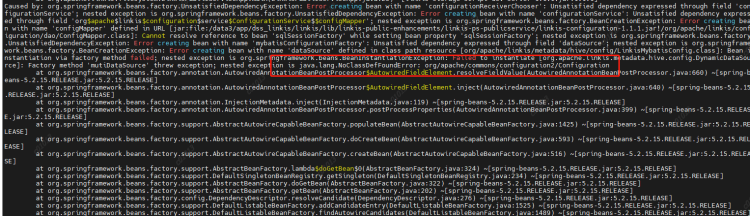
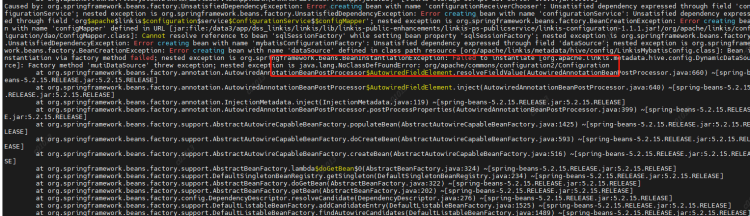 原因:LabelCommonConfig.java和GovernaceCommonConf.scala这两个类中写死了引擎的版本,修改相应版本,编译后替换掉linkis以及其他组件(包括schedulis等)里面所有包含这两个类的jar(linkis-computation-governance-common-1.1.1.jar和linkis-label-common-1.1.1.jar)
原因:LabelCommonConfig.java和GovernaceCommonConf.scala这两个类中写死了引擎的版本,修改相应版本,编译后替换掉linkis以及其他组件(包括schedulis等)里面所有包含这两个类的jar(linkis-computation-governance-common-1.1.1.jar和linkis-label-common-1.1.1.jar)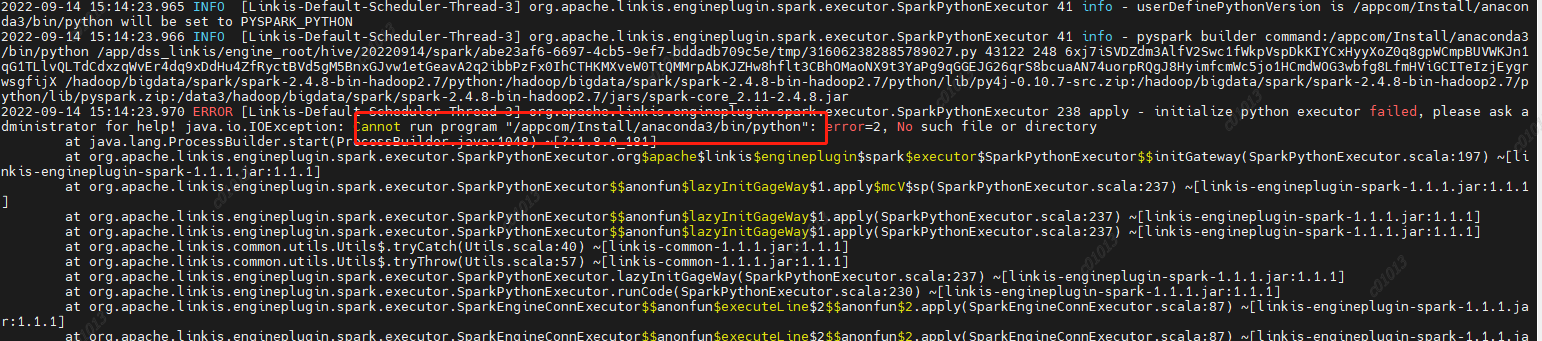 原因:未设置PYSPARK_VERSION
解决方法:
在/etc/profile下设置两个参数
原因:未设置PYSPARK_VERSION
解决方法:
在/etc/profile下设置两个参数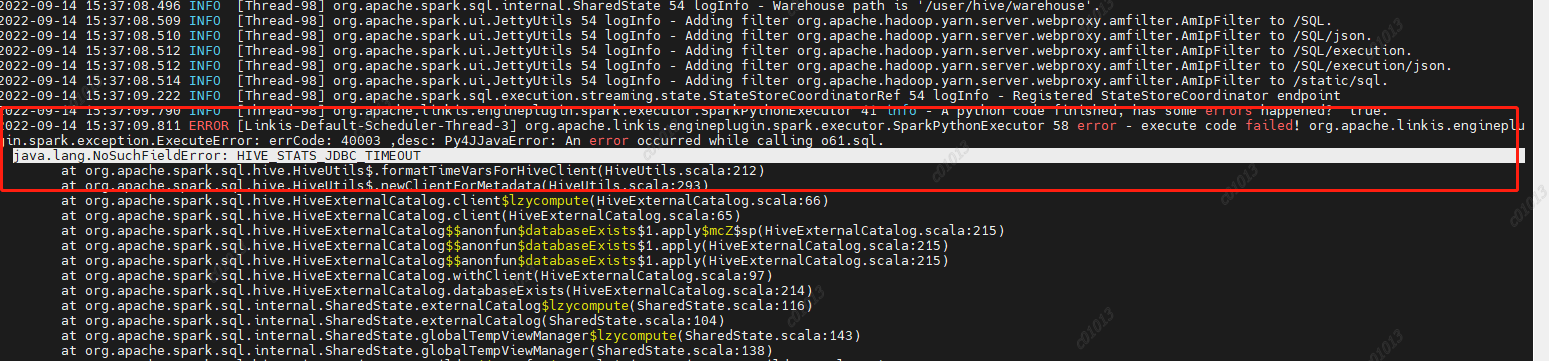 原因:spark2.4.8里面使用的是hive1.2.1的包,但是我们的hive升级到了2.1.1版本,hive2里面已经去掉了这个参数,然后spark-sql里面的代码依然是要调用hive的这个参数的,然后就报错了,
所以在spark-sql/hive代码中删除掉了HIVE_STATS_JDBC_TIMEOUT这个参数,重新编译后打包,替换spark2.4.8中的spark-hive_2.11-2.4.8.jar
原因:spark2.4.8里面使用的是hive1.2.1的包,但是我们的hive升级到了2.1.1版本,hive2里面已经去掉了这个参数,然后spark-sql里面的代码依然是要调用hive的这个参数的,然后就报错了,
所以在spark-sql/hive代码中删除掉了HIVE_STATS_JDBC_TIMEOUT这个参数,重新编译后打包,替换spark2.4.8中的spark-hive_2.11-2.4.8.jar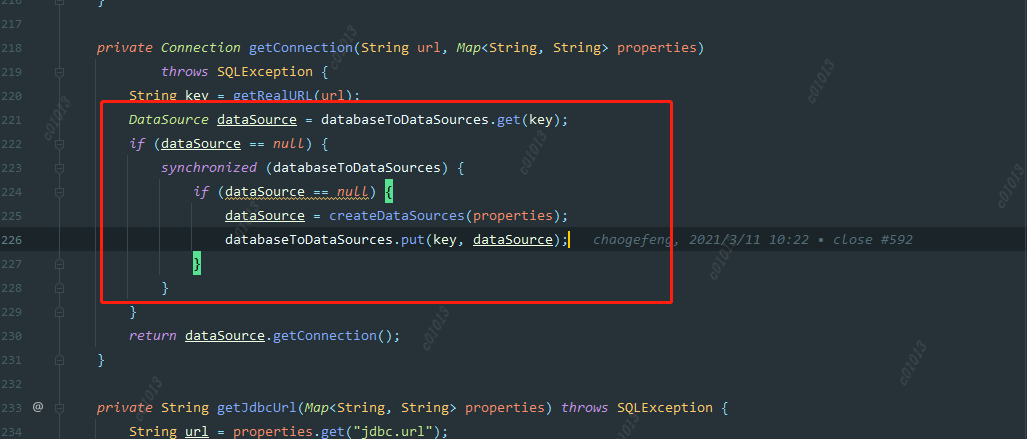 这里创建datasource的时候是根据key来判断是否创建,而这个key是jdbc url ,但这种粒度可能有点大,因为有可能是不同的用户去访问同一个数据源,比如说hive,他们的url是一样的,但是账号密码是不一样的,所以当第一个用户去创建datasource时,username已经指定了,第二个用户进来的时候,发现这个数据源存在,就直接拿这个数据源去用,而不是创建一个新的datasource,所以造成了用户B提交的代码通过A去执行了。
这里创建datasource的时候是根据key来判断是否创建,而这个key是jdbc url ,但这种粒度可能有点大,因为有可能是不同的用户去访问同一个数据源,比如说hive,他们的url是一样的,但是账号密码是不一样的,所以当第一个用户去创建datasource时,username已经指定了,第二个用户进来的时候,发现这个数据源存在,就直接拿这个数据源去用,而不是创建一个新的datasource,所以造成了用户B提交的代码通过A去执行了。
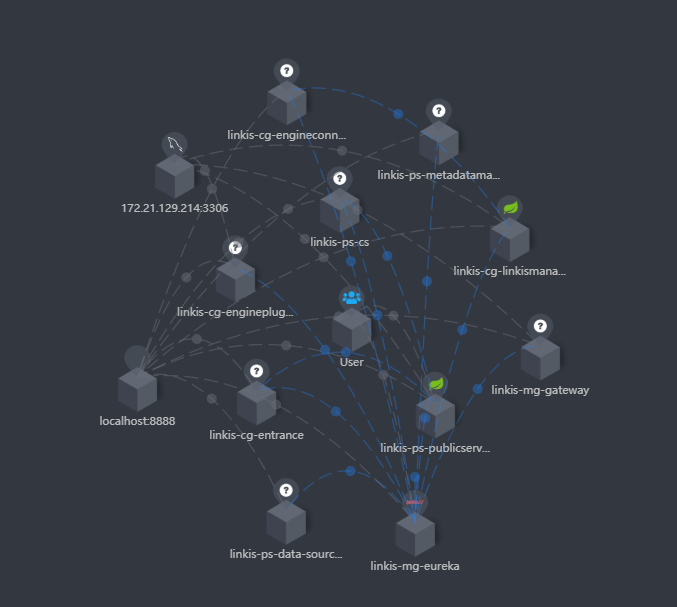 同时你也可以看清晰到在追踪中看到调用链路,如下图,也便于你定位具体服务的错误日志文件
同时你也可以看清晰到在追踪中看到调用链路,如下图,也便于你定位具体服务的错误日志文件



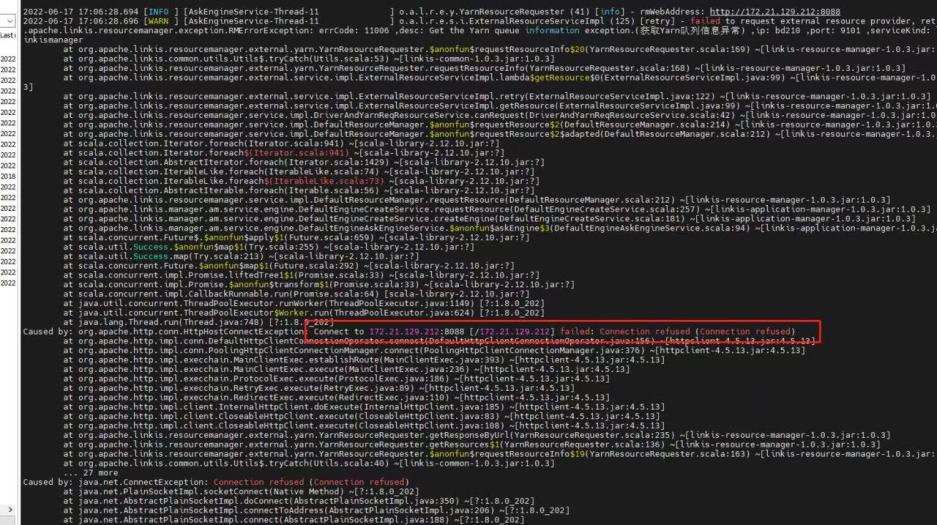
 比如qualitis举例,下面的ip和host端口,根据自己具体使用的来
比如qualitis举例,下面的ip和host端口,根据自己具体使用的来