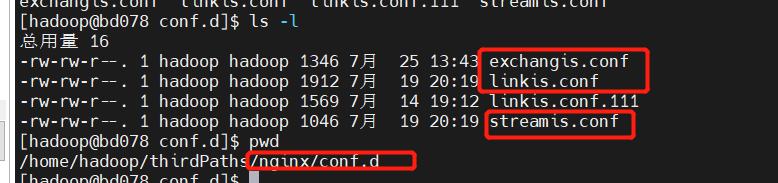
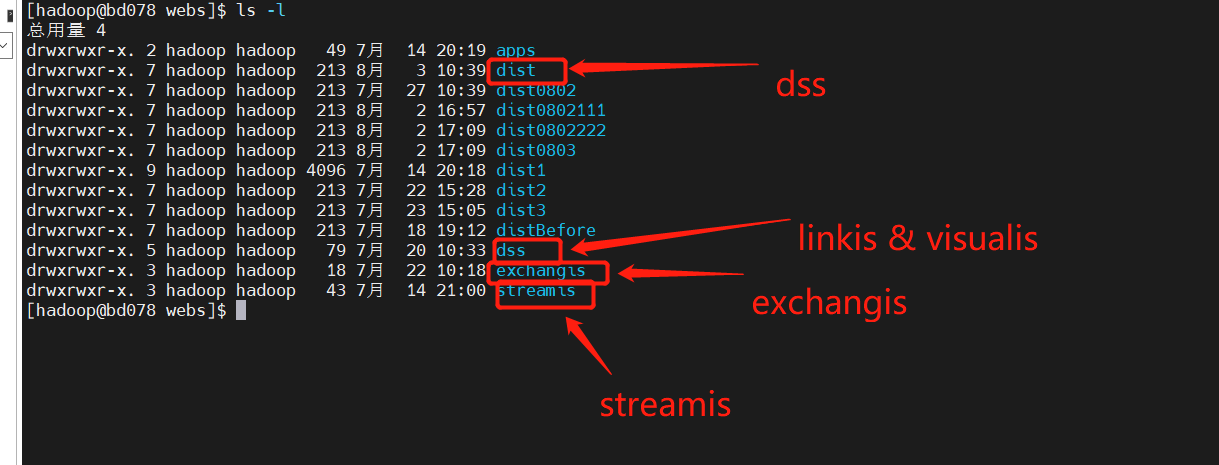
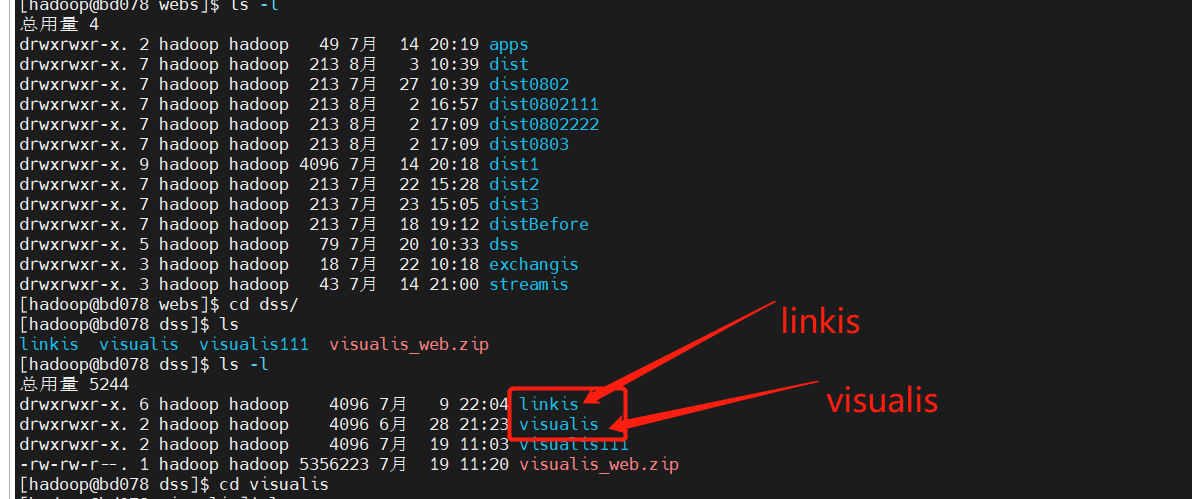
前言#
随着业务的发展和社区产品的更新迭代,我们发现Linkis1.X服务过多,可以适当进行服务合并,减少服务数量,方便部署和调试。目前Linkis服务主要分为三大类,包括计算治理服务(CG: entrance/ecp/ecm/linkismanager)、公共增强服务(PS:publicservice/datasource/cs)和微服务治理服务(MG:Gateway/Eureka)。这三类服务延伸的子服务过多,可以进行服务合并,做到将PS的服务全部合并,CG服务支持全部合并,同时支持将ecm服务单独出去。
服务合并变动#
本次服务合并主要变动如下:
- 支持Restful服务转发:修改点主要为Gateway的转发逻辑,类似于现在publicservice服务合并参数:wds.linkis.gateway.conf.publicservice.list
- 支持将RPC服务远程调用改为本地调用,类似LocalMessageSender,现在已经可以通过改Sender完成本地调用的返回
- 配置文件变动
- 服务启停脚本变动
待实现目标#
- 基本目标:合并PS服务为一个服务
- 基本目标:合并CG服务为CG-Service和ECM
- 进阶目标:合并CG服务为一个服
- 终结目标:去掉eureka、gateway变为单体服务
具体变动#
Gateway变动(org.apache.linkis.gateway.ujes.route.HaContextGatewayRouter)#
//变动前override def route(gatewayContext: GatewayContext): ServiceInstance = {
if (gatewayContext.getGatewayRoute.getRequestURI.contains(HaContextGatewayRouter.CONTEXT_SERVICE_STR) || gatewayContext.getGatewayRoute.getRequestURI.contains(HaContextGatewayRouter.OLD_CONTEXT_SERVICE_PREFIX)){ val params: util.HashMap[String, String] = gatewayContext.getGatewayRoute.getParams if (!gatewayContext.getRequest.getQueryParams.isEmpty) { for ((k, vArr) <- gatewayContext.getRequest.getQueryParams) { if (vArr.nonEmpty) { params.putIfAbsent(k, vArr.head) } } } if (gatewayContext.getRequest.getHeaders.containsKey(ContextHTTPConstant.CONTEXT_ID_STR)) { params.putIfAbsent(ContextHTTPConstant.CONTEXT_ID_STR, gatewayContext.getRequest.getHeaders.get(ContextHTTPConstant.CONTEXT_ID_STR)(0)) } if (null == params || params.isEmpty) { dealContextCreate(gatewayContext) } else { var contextId : String = null for ((key, value) <- params) { if (key.equalsIgnoreCase(ContextHTTPConstant.CONTEXT_ID_STR)) { contextId = value } } if (StringUtils.isNotBlank(contextId)) { dealContextAccess(contextId.toString, gatewayContext) } else { dealContextCreate(gatewayContext) } } }else{ null } } //变动后 override def route(gatewayContext: GatewayContext): ServiceInstance = {
if ( gatewayContext.getGatewayRoute.getRequestURI.contains( RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX ) ) { val params: util.HashMap[String, String] = gatewayContext.getGatewayRoute.getParams if (!gatewayContext.getRequest.getQueryParams.isEmpty) { for ((k, vArr) <- gatewayContext.getRequest.getQueryParams.asScala) { if (vArr.nonEmpty) { params.putIfAbsent(k, vArr.head) } } } if (gatewayContext.getRequest.getHeaders.containsKey(ContextHTTPConstant.CONTEXT_ID_STR)) { params.putIfAbsent( ContextHTTPConstant.CONTEXT_ID_STR, gatewayContext.getRequest.getHeaders.get(ContextHTTPConstant.CONTEXT_ID_STR)(0) ) } if (null == params || params.isEmpty) { dealContextCreate(gatewayContext) } else { var contextId: String = null for ((key, value) <- params.asScala) { if (key.equalsIgnoreCase(ContextHTTPConstant.CONTEXT_ID_STR)) { contextId = value } } if (StringUtils.isNotBlank(contextId)) { dealContextAccess(contextId, gatewayContext) } else { dealContextCreate(gatewayContext) } } } else { null } }
//变动前 def dealContextCreate(gatewayContext:GatewayContext):ServiceInstance = { val serviceId = findService(HaContextGatewayRouter.CONTEXT_SERVICE_STR, list => { val services = list.filter(_.contains(HaContextGatewayRouter.CONTEXT_SERVICE_STR)) services.headOption }) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (serviceInstances.size > 0) { val index = new Random().nextInt(serviceInstances.size) serviceInstances(index) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } } //变动后 def dealContextCreate(gatewayContext: GatewayContext): ServiceInstance = { val serviceId = findService( RPCConfiguration.CONTEXT_SERVICE_NAME, list => { val services = list.filter(_.contains(RPCConfiguration.CONTEXT_SERVICE_NAME)) services.headOption } ) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (serviceInstances.size > 0) { val index = new Random().nextInt(serviceInstances.size) serviceInstances(index) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } }
//变动前 def dealContextAccess(contextIdStr:String, gatewayContext: GatewayContext):ServiceInstance = { val contextId : String = { var tmpId : String = null if (serializationHelper.accepts(contextIdStr)) { val contextID : ContextID = serializationHelper.deserialize(contextIdStr).asInstanceOf[ContextID] if (null != contextID) { tmpId = contextID.getContextId } else { logger.error(s"Deserializate contextID null. contextIDStr : " + contextIdStr) } } else { logger.error(s"ContxtIDStr cannot be deserialized. contextIDStr : " + contextIdStr) } if (null == tmpId) { contextIdStr } else { tmpId } } val instances = contextIDParser.parse(contextId) var serviceId:Option[String] = None serviceId = findService(HaContextGatewayRouter.CONTEXT_SERVICE_STR, list => { val services = list.filter(_.contains(HaContextGatewayRouter.CONTEXT_SERVICE_STR)) services.headOption }) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (instances.size() > 0) { serviceId.map(ServiceInstance(_, instances.get(0))).orNull } else if (serviceInstances.size > 0) { serviceInstances(0) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } }
}//变动后def dealContextAccess(contextIdStr: String, gatewayContext: GatewayContext): ServiceInstance = { val contextId: String = { var tmpId: String = null if (serializationHelper.accepts(contextIdStr)) { val contextID: ContextID = serializationHelper.deserialize(contextIdStr).asInstanceOf[ContextID] if (null != contextID) { tmpId = contextID.getContextId } else { logger.error(s"Deserializate contextID null. contextIDStr : " + contextIdStr) } } else { logger.error(s"ContxtIDStr cannot be deserialized. contextIDStr : " + contextIdStr) } if (null == tmpId) { contextIdStr } else { tmpId } } val instances = contextIDParser.parse(contextId) var serviceId: Option[String] = None serviceId = findService( RPCConfiguration.CONTEXT_SERVICE_NAME, list => { val services = list.filter(_.contains(RPCConfiguration.CONTEXT_SERVICE_NAME)) services.headOption } ) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (instances.size() > 0) { serviceId.map(ServiceInstance(_, instances.get(0))).orNull } else if (serviceInstances.size > 0) { serviceInstances(0) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } }
//变动前object HaContextGatewayRouter{ val CONTEXT_ID_STR:String = "contextId" val CONTEXT_SERVICE_STR:String = "ps-cs" @Deprecated val OLD_CONTEXT_SERVICE_PREFIX = "contextservice" val CONTEXT_REGEX: Regex = (normalPath(API_URL_PREFIX) + "rest_[a-zA-Z][a-zA-Z_0-9]*/(v\\d+)/contextservice/" + ".+").r}//变动后object HaContextGatewayRouter {
val CONTEXT_ID_STR: String = "contextId"
@deprecated("please use RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX") val CONTEXT_SERVICE_REQUEST_PREFIX = RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX
@deprecated("please use RPCConfiguration.CONTEXT_SERVICE_NAME") val CONTEXT_SERVICE_NAME: String = if ( RPCConfiguration.ENABLE_PUBLIC_SERVICE.getValue && RPCConfiguration.PUBLIC_SERVICE_LIST .exists(_.equalsIgnoreCase(RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX)) ) { RPCConfiguration.PUBLIC_SERVICE_APPLICATION_NAME.getValue } else { RPCConfiguration.CONTEXT_SERVICE_APPLICATION_NAME.getValue }
val CONTEXT_REGEX: Regex = (normalPath(API_URL_PREFIX) + "rest_[a-zA-Z][a-zA-Z_0-9]*/(v\\d+)/contextservice/" + ".+").r
}RPC服务变动(org.apache.linkis.rpc.conf.RPCConfiguration)#
//变动前val BDP_RPC_BROADCAST_THREAD_SIZE: CommonVars[Integer] = CommonVars("wds.linkis.rpc.broadcast.thread.num", new Integer(25))//变动后val BDP_RPC_BROADCAST_THREAD_SIZE: CommonVars[Integer] = CommonVars("wds.linkis.rpc.broadcast.thread.num", 25)
//变动前val PUBLIC_SERVICE_LIST: Array[String] = CommonVars("wds.linkis.gateway.conf.publicservice.list", "query,jobhistory,application,configuration,filesystem,udf,variable,microservice,errorcode,bml,datasource").getValue.split(",")//变动后val PUBLIC_SERVICE_LIST: Array[String] = CommonVars("wds.linkis.gateway.conf.publicservice.list", "cs,contextservice,data-source-manager,metadataquery,metadatamanager,query,jobhistory,application,configuration,filesystem,udf,variable,microservice,errorcode,bml,datasource").getValue.split(",")
配置文件变动#
##去除部分
#删除如下配置文件linkis-dist/package/conf/linkis-ps-cs.propertieslinkis-dist/package/conf/linkis-ps-data-source-manager.propertieslinkis-dist/package/conf/linkis-ps-metadataquery.properties
##修改部分
#修改linkis-dist/package/conf/linkis-ps-publicservice.properties#restful修改前wds.linkis.server.restful.scan.packages=org.apache.linkis.jobhistory.restful,org.apache.linkis.variable.restful,org.apache.linkis.configuration.restful,org.apache.linkis.udf.api,org.apache.linkis.filesystem.restful,org.apache.linkis.filesystem.restful,org.apache.linkis.instance.label.restful,org.apache.linkis.metadata.restful.api,org.apache.linkis.cs.server.restful,org.apache.linkis.bml.restful,org.apache.linkis.errorcode.server.restful
#restful修改后wds.linkis.server.restful.scan.packages=org.apache.linkis.cs.server.restful,org.apache.linkis.datasourcemanager.core.restful,org.apache.linkis.metadata.query.server.restful,org.apache.linkis.jobhistory.restful,org.apache.linkis.variable.restful,org.apache.linkis.configuration.restful,org.apache.linkis.udf.api,org.apache.linkis.filesystem.restful,org.apache.linkis.filesystem.restful,org.apache.linkis.instance.label.restful,org.apache.linkis.metadata.restful.api,org.apache.linkis.cs.server.restful,org.apache.linkis.bml.restful,org.apache.linkis.errorcode.server.restful
#mybatis修改前wds.linkis.server.mybatis.mapperLocations=classpath:org/apache/linkis/jobhistory/dao/impl/*.xml,classpath:org/apache/linkis/variable/dao/impl/*.xml,classpath:org/apache/linkis/configuration/dao/impl/*.xml,classpath:org/apache/linkis/udf/dao/impl/*.xml,classpath:org/apache/linkis/instance/label/dao/impl/*.xml,classpath:org/apache/linkis/metadata/hive/dao/impl/*.xml,org/apache/linkis/metadata/dao/impl/*.xml,classpath:org/apache/linkis/bml/dao/impl/*.xml
wds.linkis.server.mybatis.typeAliasesPackage=org.apache.linkis.configuration.entity,org.apache.linkis.jobhistory.entity,org.apache.linkis.udf.entity,org.apache.linkis.variable.entity,org.apache.linkis.instance.label.entity,org.apache.linkis.manager.entity,org.apache.linkis.metadata.domain,org.apache.linkis.bml.entity
wds.linkis.server.mybatis.BasePackage=org.apache.linkis.jobhistory.dao,org.apache.linkis.variable.dao,org.apache.linkis.configuration.dao,org.apache.linkis.udf.dao,org.apache.linkis.instance.label.dao,org.apache.linkis.metadata.hive.dao,org.apache.linkis.metadata.dao,org.apache.linkis.bml.dao,org.apache.linkis.errorcode.server.dao,org.apache.linkis.publicservice.common.lock.dao
#mybatis修改后wds.linkis.server.mybatis.mapperLocations=classpath*:org/apache/linkis/cs/persistence/dao/impl/*.xml,classpath:org/apache/linkis/datasourcemanager/core/dao/mapper/*.xml,classpath:org/apache/linkis/jobhistory/dao/impl/*.xml,classpath:org/apache/linkis/variable/dao/impl/*.xml,classpath:org/apache/linkis/configuration/dao/impl/*.xml,classpath:org/apache/linkis/udf/dao/impl/*.xml,classpath:org/apache/linkis/instance/label/dao/impl/*.xml,classpath:org/apache/linkis/metadata/hive/dao/impl/*.xml,org/apache/linkis/metadata/dao/impl/*.xml,classpath:org/apache/linkis/bml/dao/impl/*.xml
wds.linkis.server.mybatis.typeAliasesPackage=org.apache.linkis.cs.persistence.entity,org.apache.linkis.datasourcemanager.common.domain,org.apache.linkis.datasourcemanager.core.vo,org.apache.linkis.configuration.entity,org.apache.linkis.jobhistory.entity,org.apache.linkis.udf.entity,org.apache.linkis.variable.entity,org.apache.linkis.instance.label.entity,org.apache.linkis.manager.entity,org.apache.linkis.metadata.domain,org.apache.linkis.bml.entity
wds.linkis.server.mybatis.BasePackage=org.apache.linkis.cs.persistence.dao,org.apache.linkis.datasourcemanager.core.dao,org.apache.linkis.jobhistory.dao,org.apache.linkis.variable.dao,org.apache.linkis.configuration.dao,org.apache.linkis.udf.dao,org.apache.linkis.instance.label.dao,org.apache.linkis.metadata.hive.dao,org.apache.linkis.metadata.dao,org.apache.linkis.bml.dao,org.apache.linkis.errorcode.server.dao,org.apache.linkis.publicservice.common.lock.dao部署脚本变动(linkis-dist/package/sbin/linkis-start-all.sh)#
#服务启动脚本去掉如下部分
#linkis-ps-csSERVER_NAME="ps-cs"SERVER_IP=$CS_INSTALL_IPstartApp
if [ "$ENABLE_METADATA_QUERY" == "true" ]; then #linkis-ps-data-source-manager SERVER_NAME="ps-data-source-manager" SERVER_IP=$DATASOURCE_MANAGER_INSTALL_IP startApp
#linkis-ps-metadataquery SERVER_NAME="ps-metadataquery" SERVER_IP=$METADATA_QUERY_INSTALL_IP startAppfi
#linkis-ps-csSERVER_NAME="ps-cs"SERVER_IP=$CS_INSTALL_IPcheckServer
if [ "$ENABLE_METADATA_QUERY" == "true" ]; then #linkis-ps-data-source-manager SERVER_NAME="ps-data-source-manager" SERVER_IP=$DATASOURCE_MANAGER_INSTALL_IP checkServer
#linkis-ps-metadataquery SERVER_NAME="ps-metadataquery" SERVER_IP=$METADATA_QUERY_INSTALL_IP checkServerfi
#服务停止脚本去掉如下部分#linkis-ps-csSERVER_NAME="ps-cs"SERVER_IP=$CS_INSTALL_IPstopApp
if [ "$ENABLE_METADATA_QUERY" == "true" ]; then #linkis-ps-data-source-manager SERVER_NAME="ps-data-source-manager" SERVER_IP=$DATASOURCE_MANAGER_INSTALL_IP stopApp
#linkis-ps-metadataquery SERVER_NAME="ps-metadataquery" SERVER_IP=$METADATA_QUERY_INSTALL_IP stopAppfi
更多服务合并变动细节参见:https://github.com/apache/incubator-linkis/pull/2927/files

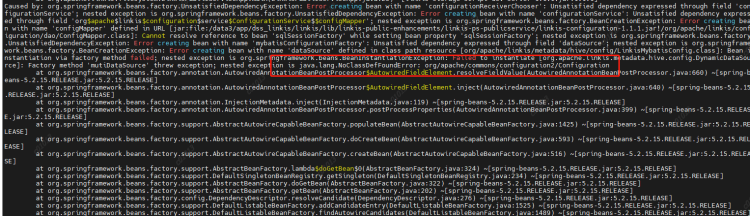
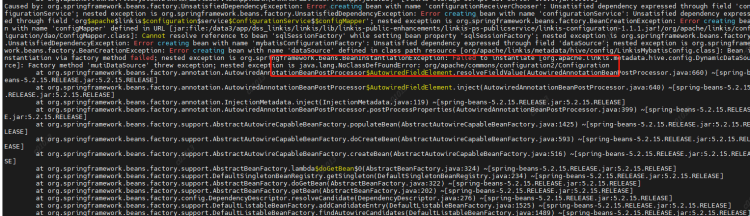 原因:LabelCommonConfig.java和GovernaceCommonConf.scala这两个类中写死了引擎的版本,修改相应版本,编译后替换掉linkis以及其他组件(包括schedulis等)里面所有包含这两个类的jar(linkis-computation-governance-common-1.1.1.jar和linkis-label-common-1.1.1.jar)
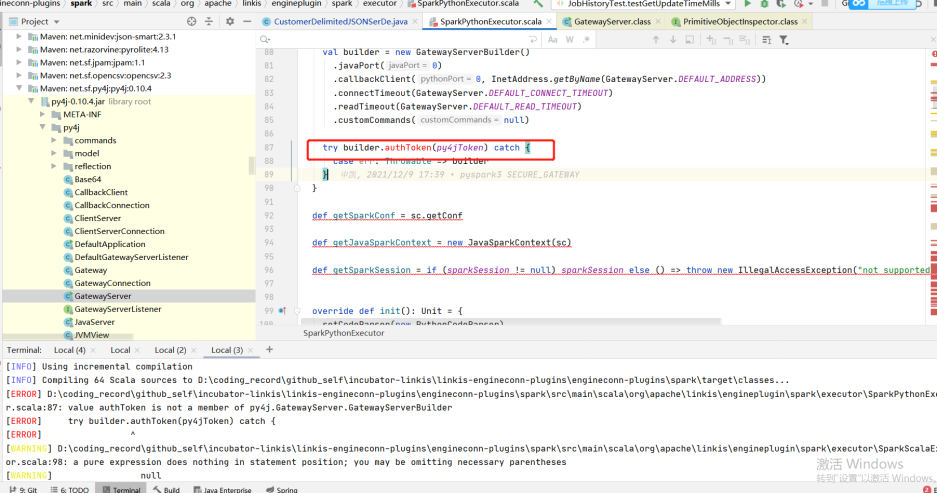
原因:LabelCommonConfig.java和GovernaceCommonConf.scala这两个类中写死了引擎的版本,修改相应版本,编译后替换掉linkis以及其他组件(包括schedulis等)里面所有包含这两个类的jar(linkis-computation-governance-common-1.1.1.jar和linkis-label-common-1.1.1.jar)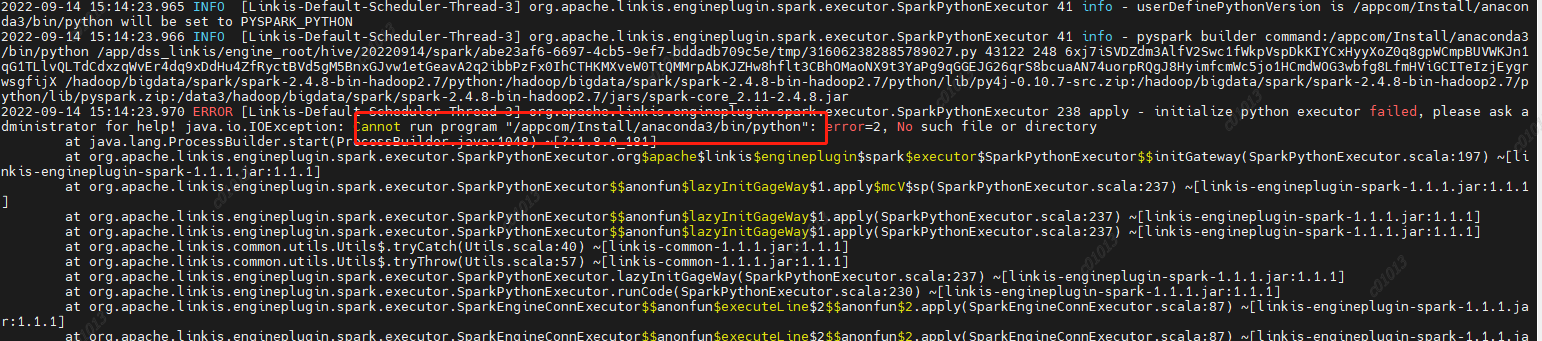 原因:未设置PYSPARK_VERSION
解决方法:
在/etc/profile下设置两个参数
原因:未设置PYSPARK_VERSION
解决方法:
在/etc/profile下设置两个参数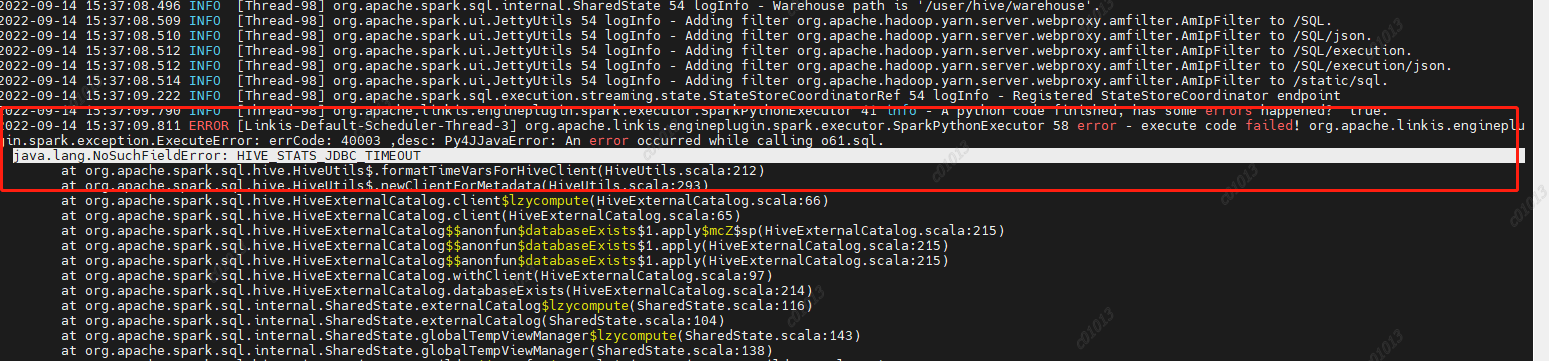 原因:spark2.4.8里面使用的是hive1.2.1的包,但是我们的hive升级到了2.1.1版本,hive2里面已经去掉了这个参数,然后spark-sql里面的代码依然是要调用hive的这个参数的,然后就报错了,
所以在spark-sql/hive代码中删除掉了HIVE_STATS_JDBC_TIMEOUT这个参数,重新编译后打包,替换spark2.4.8中的spark-hive_2.11-2.4.8.jar
原因:spark2.4.8里面使用的是hive1.2.1的包,但是我们的hive升级到了2.1.1版本,hive2里面已经去掉了这个参数,然后spark-sql里面的代码依然是要调用hive的这个参数的,然后就报错了,
所以在spark-sql/hive代码中删除掉了HIVE_STATS_JDBC_TIMEOUT这个参数,重新编译后打包,替换spark2.4.8中的spark-hive_2.11-2.4.8.jar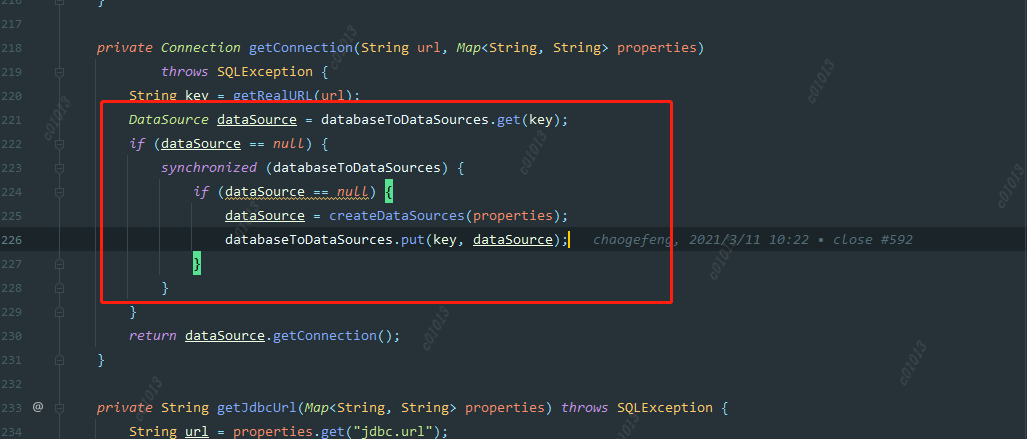 这里创建datasource的时候是根据key来判断是否创建,而这个key是jdbc url ,但这种粒度可能有点大,因为有可能是不同的用户去访问同一个数据源,比如说hive,他们的url是一样的,但是账号密码是不一样的,所以当第一个用户去创建datasource时,username已经指定了,第二个用户进来的时候,发现这个数据源存在,就直接拿这个数据源去用,而不是创建一个新的datasource,所以造成了用户B提交的代码通过A去执行了。
这里创建datasource的时候是根据key来判断是否创建,而这个key是jdbc url ,但这种粒度可能有点大,因为有可能是不同的用户去访问同一个数据源,比如说hive,他们的url是一样的,但是账号密码是不一样的,所以当第一个用户去创建datasource时,username已经指定了,第二个用户进来的时候,发现这个数据源存在,就直接拿这个数据源去用,而不是创建一个新的datasource,所以造成了用户B提交的代码通过A去执行了。
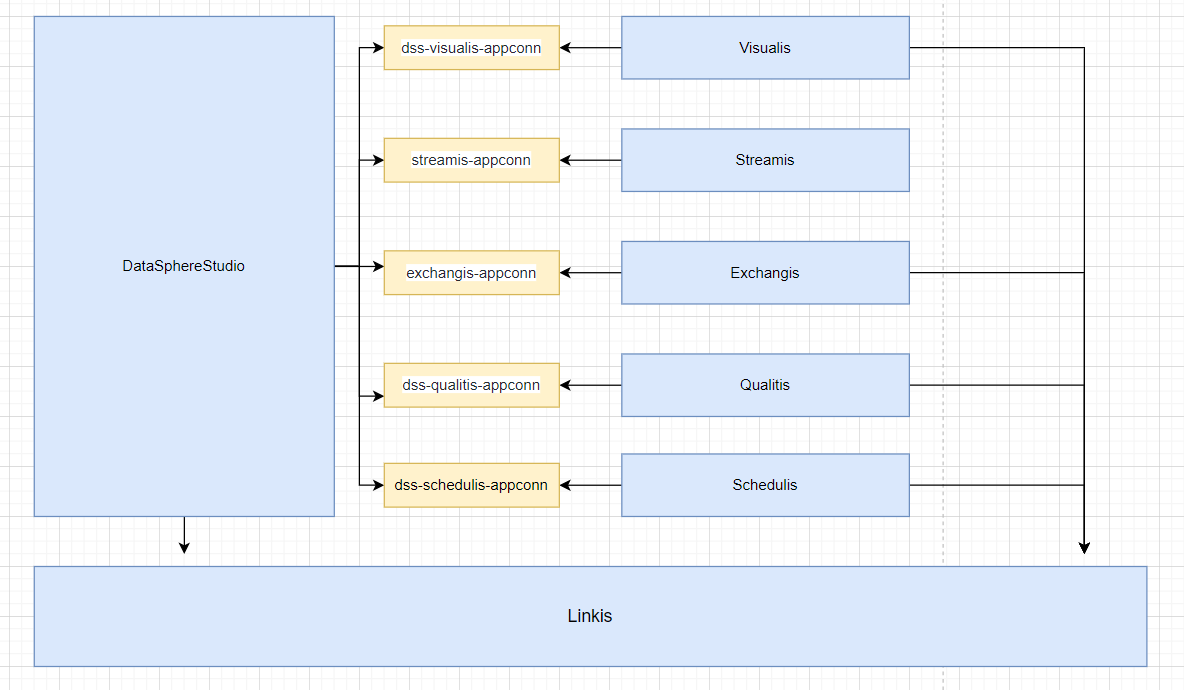
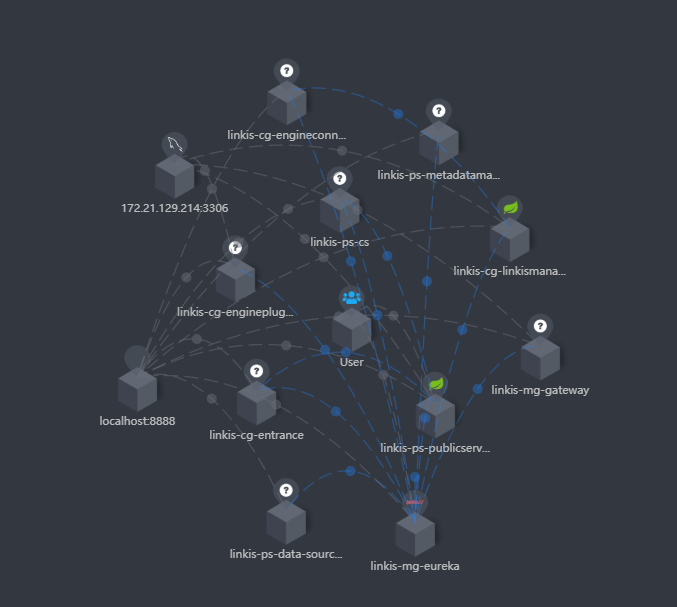 同时你也可以看清晰到在追踪中看到调用链路,如下图,也便于你定位具体服务的错误日志文件
同时你也可以看清晰到在追踪中看到调用链路,如下图,也便于你定位具体服务的错误日志文件

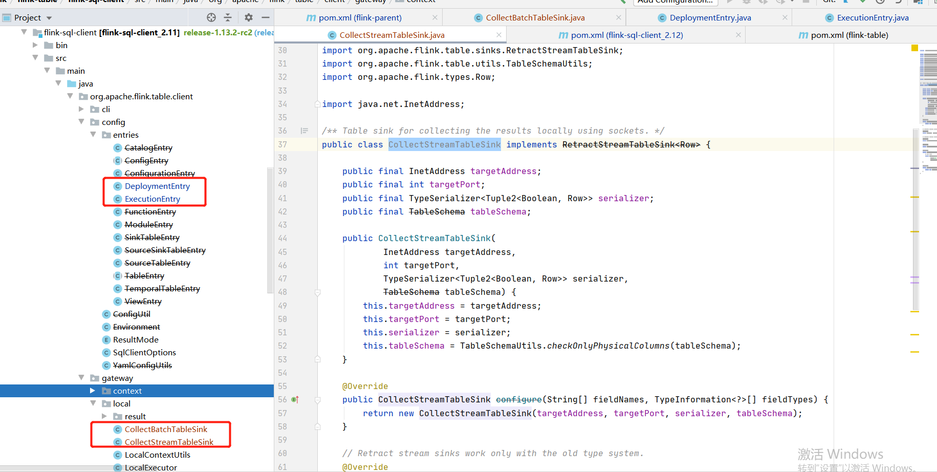
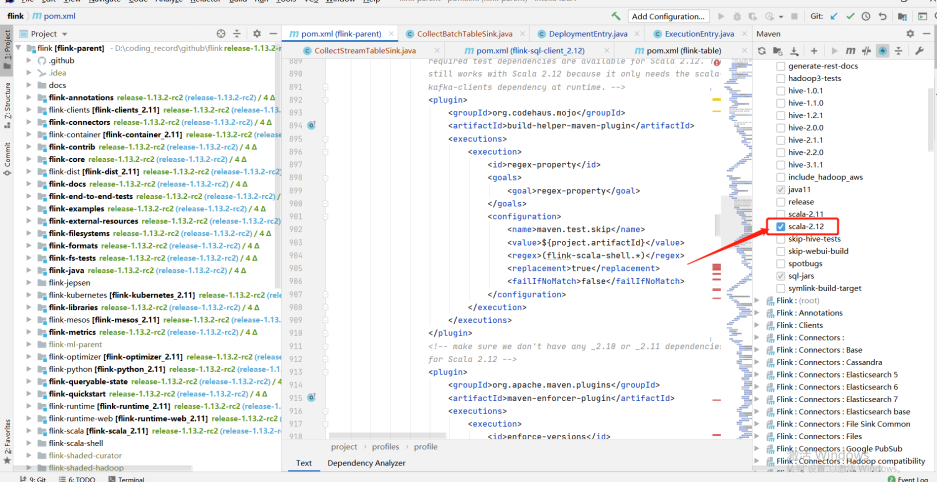

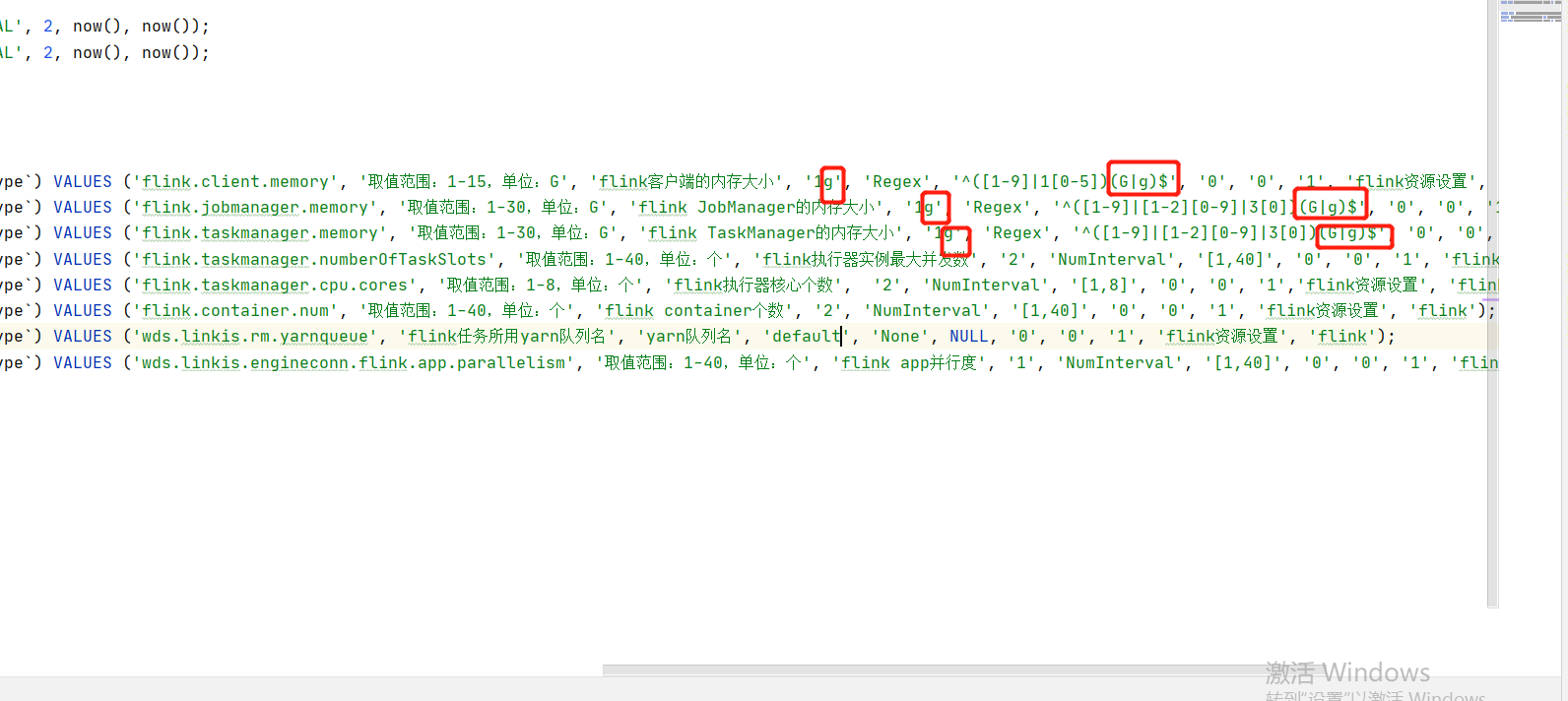

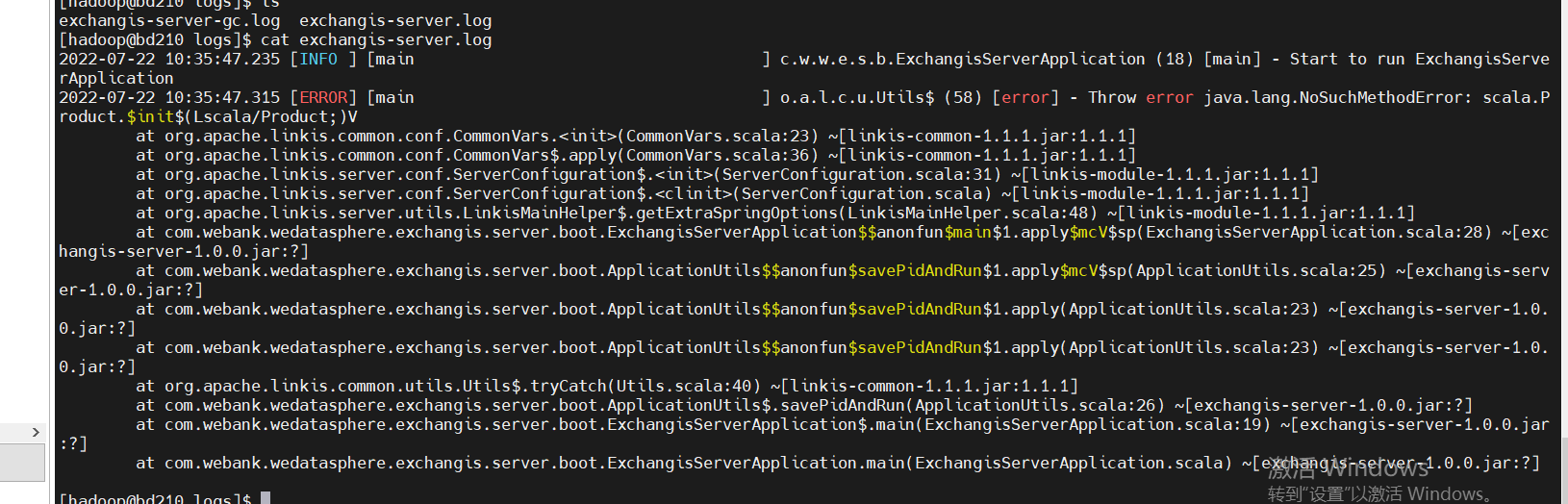
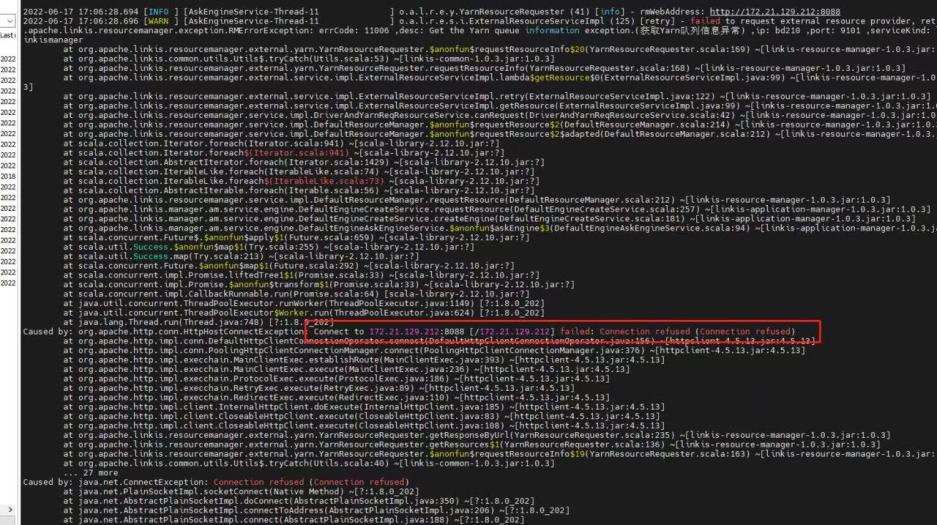
 比如qualitis举例,下面的ip和host端口,根据自己具体使用的来
比如qualitis举例,下面的ip和host端口,根据自己具体使用的来