Foreword#
With the development of business and the update and iteration of community products, we found that Linkis1 There are too many .X services, and services can be merged appropriately to reduce the number of services and facilitate deployment and debugging. At present, Linkis services are mainly divided into three categories, including computing governance services (CG: entrance/ecp/ecm/linkismanager), public enhancement services (PS: publicservice/datasource/cs) and microservice governance services (MG: Gateway/Eureka) . There are too many sub-services extended by these three types of services, and services can be merged, so that all PS services can be merged, CG services can be merged, and ecm services can be separated out.
Service merge changes#
The main changes of this service merge are as follows:
- Support Restful service forwarding: The modification point is mainly the forwarding logic of Gateway, similar to the current publicservice service merge parameter: wds.linkis.gateway.conf.publicservice.list
- Support Change the remote call of the RPC service to a local call, similar to LocalMessageSender, and now it is possible to complete the return of the local call by changing the Sender
- Configuration file changes
- Service start and stop script changes
To be achieved#
- Basic goal: merge PS services into one service
- Basic goal: merge CG service into CG-Service and ECM
- Advanced goal: merge CG services into one server
- Final goal: remove eureka, gateway into single service
Specific changes#
Gateway changes (org.apache.linkis.gateway.ujes.route.HaContextGatewayRouter)#
//Override before changing def route(gatewayContext: GatewayContext): ServiceInstance = {
if (gatewayContext.getGatewayRoute.getRequestURI.contains(HaContextGatewayRouter.CONTEXT_SERVICE_STR) || gatewayContext.getGatewayRoute.getRequestURI.contains(HaContextGatewayRouter.OLD_CONTEXT_SERVICE_PREFIX)){ val params: util.HashMap[String, String] = gatewayContext.getGatewayRoute.getParams if (!gatewayContext.getRequest.getQueryParams.isEmpty) { for ((k, vArr) <- gatewayContext.getRequest.getQueryParams) { if (vArr.nonEmpty) { params.putIfAbsent(k, vArr.head) } } } if (gatewayContext.getRequest.getHeaders.containsKey(ContextHTTPConstant.CONTEXT_ID_STR)) { params.putIfAbsent(ContextHTTPConstant.CONTEXT_ID_STR, gatewayContext.getRequest.getHeaders.get(ContextHTTPConstant.CONTEXT_ID_STR)(0)) } if (null == params || params.isEmpty) { dealContextCreate(gatewayContext) } else { var contextId : String = null for ((key, value) <- params) { if (key.equalsIgnoreCase(ContextHTTPConstant.CONTEXT_ID_STR)) { contextId = value } } if (StringUtils.isNotBlank(contextId)) { dealContextAccess(contextId.toString, gatewayContext) } else { dealContextCreate(gatewayContext) } } }else{ null } } //after modification override def route(gatewayContext: GatewayContext): ServiceInstance = {
if ( gatewayContext.getGatewayRoute.getRequestURI.contains( RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX ) ) { val params: util.HashMap[String, String] = gatewayContext.getGatewayRoute.getParams if (!gatewayContext.getRequest.getQueryParams.isEmpty) { for ((k, vArr) <- gatewayContext.getRequest.getQueryParams.asScala) { if (vArr.nonEmpty) { params.putIfAbsent(k, vArr.head) } } } if (gatewayContext.getRequest.getHeaders.containsKey(ContextHTTPConstant.CONTEXT_ID_STR)) { params.putIfAbsent( ContextHTTPConstant.CONTEXT_ID_STR, gatewayContext.getRequest.getHeaders.get(ContextHTTPConstant.CONTEXT_ID_STR)(0) ) } if (null == params || params.isEmpty) { dealContextCreate(gatewayContext) } else { var contextId: String = null for ((key, value) <- params.asScala) { if (key.equalsIgnoreCase(ContextHTTPConstant.CONTEXT_ID_STR)) { contextId = value } } if (StringUtils.isNotBlank(contextId)) { dealContextAccess(contextId, gatewayContext) } else { dealContextCreate(gatewayContext) } } } else { null } }
// before modification def dealContextCreate(gatewayContext:GatewayContext):ServiceInstance = { val serviceId = findService(HaContextGatewayRouter.CONTEXT_SERVICE_STR, list => { val services = list.filter(_.contains(HaContextGatewayRouter.CONTEXT_SERVICE_STR)) services.headOption }) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (serviceInstances.size > 0) { val index = new Random().nextInt(serviceInstances.size) serviceInstances(index) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } } //after modification def dealContextCreate(gatewayContext: GatewayContext): ServiceInstance = { val serviceId = findService( RPCConfiguration.CONTEXT_SERVICE_NAME, list => { val services = list.filter(_.contains(RPCConfiguration.CONTEXT_SERVICE_NAME)) services.headOption } ) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (serviceInstances.size > 0) { val index = new Random().nextInt(serviceInstances.size) serviceInstances(index) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } }
// before modification def dealContextAccess(contextIdStr:String, gatewayContext: GatewayContext):ServiceInstance = { val contextId : String = { var tmpId : String = null if (serializationHelper.accepts(contextIdStr)) { val contextID : ContextID = serializationHelper.deserialize(contextIdStr).asInstanceOf[ContextID] if (null != contextID) { tmpId = contextID.getContextId } else { logger.error(s"Deserializate contextID null. contextIDStr : " + contextIdStr) } } else { logger.error(s"ContxtIDStr cannot be deserialized. contextIDStr : " + contextIdStr) } if (null == tmpId) { contextIdStr } else { tmpId } } val instances = contextIDParser.parse(contextId) var serviceId:Option[String] = None serviceId = findService(HaContextGatewayRouter.CONTEXT_SERVICE_STR, list => { val services = list.filter(_.contains(HaContextGatewayRouter.CONTEXT_SERVICE_STR)) services.headOption }) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (instances.size() > 0) { serviceId.map(ServiceInstance(_, instances.get(0))).orNull } else if (serviceInstances.size > 0) { serviceInstances(0) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } }
}//after modificationdef dealContextAccess(contextIdStr: String, gatewayContext: GatewayContext): ServiceInstance = { val contextId: String = { var tmpId: String = null if (serializationHelper.accepts(contextIdStr)) { val contextID: ContextID = serializationHelper.deserialize(contextIdStr).asInstanceOf[ContextID] if (null != contextID) { tmpId = contextID.getContextId } else { logger.error(s"Deserializate contextID null. contextIDStr : " + contextIdStr) } } else { logger.error(s"ContxtIDStr cannot be deserialized. contextIDStr : " + contextIdStr) } if (null == tmpId) { contextIdStr } else { tmpId } } val instances = contextIDParser.parse(contextId) var serviceId: Option[String] = None serviceId = findService( RPCConfiguration.CONTEXT_SERVICE_NAME, list => { val services = list.filter(_.contains(RPCConfiguration.CONTEXT_SERVICE_NAME)) services.headOption } ) val serviceInstances = ServiceInstanceUtils.getRPCServerLoader.getServiceInstances(serviceId.orNull) if (instances.size() > 0) { serviceId.map(ServiceInstance(_, instances.get(0))).orNull } else if (serviceInstances.size > 0) { serviceInstances(0) } else { logger.error(s"No valid instance for service : " + serviceId.orNull) null } }
// before modificationobject HaContextGatewayRouter{ val CONTEXT_ID_STR:String = "contextId" val CONTEXT_SERVICE_STR:String = "ps-cs" @Deprecated val OLD_CONTEXT_SERVICE_PREFIX = "contextservice" val CONTEXT_REGEX: Regex = (normalPath(API_URL_PREFIX) + "rest_[a-zA-Z][a-zA-Z_0-9]*/(v\\d+)/contextservice/" + ".+").r}//after modificationobject HaContextGatewayRouter {
val CONTEXT_ID_STR: String = "contextId"
@deprecated("please use RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX") val CONTEXT_SERVICE_REQUEST_PREFIX = RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX
@deprecated("please use RPCConfiguration.CONTEXT_SERVICE_NAME") val CONTEXT_SERVICE_NAME: String = if ( RPCConfiguration.ENABLE_PUBLIC_SERVICE.getValue && RPCConfiguration.PUBLIC_SERVICE_LIST .exists(_.equalsIgnoreCase(RPCConfiguration.CONTEXT_SERVICE_REQUEST_PREFIX)) ) { RPCConfiguration.PUBLIC_SERVICE_APPLICATION_NAME.getValue } else { RPCConfiguration.CONTEXT_SERVICE_APPLICATION_NAME.getValue }
val CONTEXT_REGEX: Regex = (normalPath(API_URL_PREFIX) + "rest_[a-zA-Z][a-zA-Z_0-9]*/(v\\d+)/contextservice/" + ".+").r
}RPC Service Change(org.apache.linkis.rpc.conf.RPCConfiguration)#
//before modificationval BDP_RPC_BROADCAST_THREAD_SIZE: CommonVars[Integer] = CommonVars("wds.linkis.rpc.broadcast.thread.num", new Integer(25))//after modificationval BDP_RPC_BROADCAST_THREAD_SIZE: CommonVars[Integer] = CommonVars("wds.linkis.rpc.broadcast.thread.num", 25)
//before modificationval PUBLIC_SERVICE_LIST: Array[String] = CommonVars("wds.linkis.gateway.conf.publicservice.list", "query,jobhistory,application,configuration,filesystem,udf,variable,microservice,errorcode,bml,datasource").getValue .split(",") //after change val PUBLIC_SERVICE_LIST: Array[String] = CommonVars("wds.linkis.gateway.conf.publicservice.list", "cs,contextservice,data-source-manager,metadataquery,metadatamanager, query,jobhistory,application,configuration,filesystem,udf,variable,microservice,errorcode,bml,datasource").getValue.split(",")
Configuration file changes#
##Remove part #Delete the
following configuration files linkis-dist/package/conf/linkis-ps-cs.properties linkis-dist/package/conf/linkis-ps-data-source-manager.propertieslinkis-dist/package/conf/linkis-ps-metadataquery.properties
##modified part
#modify linkis-dist/package/conf/linkis-ps-publicservice.properties#restful before modificationwds.linkis.server.restful.scan.packages=org.apache.linkis.jobhistory.restful,org.apache.linkis.variable.restful,org.apache.linkis.configuration.restful,org.apache.linkis.udf.api,org.apache.linkis.filesystem.restful,org.apache.linkis.filesystem.restful,org.apache.linkis.instance.label.restful,org.apache.linkis.metadata.restful.api,org.apache.linkis.cs.server.restful,org.apache.linkis.bml.restful,org.apache.linkis.errorcode.server.restful
#restful after modificationwds.linkis.server.restful.scan.packages=org.apache.linkis.cs.server.restful,org.apache.linkis.datasourcemanager.core.restful,org.apache.linkis.metadata.query.server.restful,org.apache.linkis.jobhistory.restful,org.apache.linkis.variable.restful,org.apache.linkis.configuration.restful,org.apache.linkis.udf.api,org.apache.linkis.filesystem.restful,org.apache.linkis.filesystem.restful,org.apache.linkis.instance.label.restful,org.apache.linkis.metadata.restful.api,org.apache.linkis.cs.server.restful,org.apache.linkis.bml.restful,org.apache.linkis.errorcode.server.restful
#mybatis before modificationwds.linkis.server.mybatis.mapperLocations=classpath:org/apache/linkis/jobhistory/dao/impl/*.xml,classpath:org/apache/linkis/variable/dao/impl/*.xml,classpath:org/apache/linkis/configuration/dao/impl/*.xml,classpath:org/apache/linkis/udf/dao/impl/*.xml,classpath:org/apache/linkis/instance/label/dao/impl/*.xml,classpath:org/apache/linkis/metadata/hive/dao/impl/*.xml,org/apache/linkis/metadata/dao/impl/*.xml,classpath:org/apache/linkis/bml/dao/impl/*.xml
wds.linkis.server.mybatis.typeAliasesPackage=org.apache.linkis.configuration.entity,org.apache.linkis.jobhistory.entity,org.apache.linkis.udf.entity,org.apache.linkis.variable.entity,org.apache.linkis.instance.label.entity,org.apache.linkis.manager.entity,org.apache.linkis.metadata.domain,org.apache.linkis.bml.entity
wds.linkis.server.mybatis.BasePackage=org.apache.linkis.jobhistory.dao,org.apache.linkis.variable.dao,org.apache.linkis.configuration.dao,org.apache.linkis.udf.dao,org.apache.linkis.instance.label.dao,org.apache.linkis.metadata.hive.dao,org.apache.linkis.metadata.dao,org.apache.linkis.bml.dao,org.apache.linkis.errorcode.server.dao,org.apache.linkis.publicservice.common.lock.dao
#mybatis after modificationwds.linkis.server.mybatis.mapperLocations=classpath*:org/apache/linkis/cs/persistence/dao/impl/*.xml,classpath:org/apache/linkis/datasourcemanager/core/dao/mapper/*.xml,classpath:org/apache/linkis/jobhistory/dao/impl/*.xml,classpath:org/apache/linkis/variable/dao/impl/*.xml,classpath:org/apache/linkis/configuration/dao/impl/*.xml,classpath:org/apache/linkis/udf/dao/impl/*.xml,classpath:org/apache/linkis/instance/label/dao/impl/*.xml,classpath:org/apache/linkis/metadata/hive/dao/impl/*.xml,org/apache/linkis/metadata/dao/impl/*.xml,classpath:org/apache/linkis/bml/dao/impl/*.xml
wds.linkis.server.mybatis.typeAliasesPackage=org.apache.linkis.cs.persistence.entity,org.apache.linkis.datasourcemanager.common.domain,org.apache.linkis.datasourcemanager.core.vo,org.apache.linkis.configuration.entity,org.apache.linkis.jobhistory.entity,org.apache.linkis.udf.entity,org.apache.linkis.variable.entity,org.apache.linkis.instance.label.entity,org.apache.linkis.manager.entity,org.apache.linkis.metadata.domain,org.apache.linkis.bml.entity
wds.linkis.server.mybatis.BasePackage=org.apache.linkis.cs.persistence.dao,org.apache.linkis.datasourcemanager.core.dao,org.apache.linkis.jobhistory.dao,org.apache.linkis. variable.dao,org.apache.linkis.configuration.dao,org.apache.linkis.udf.dao,org.apache.linkis.instance.label.dao,org.apache.linkis.metadata.hive.dao,org. apache.linkis.metadata.dao,org.apache.linkis.bml.dao,org.apache.linkis.errorcode.server.dao,org.apache.linkis.publicservice.common.lock.dao Deployment script changes (linkis-dist/package/sbin/linkis-start-all.sh)#
startup script remove the following part
#linkis-ps-cs SERVER_NAME="ps-cs" SERVER_IP=$CS_INSTALL_IP startApp
if [ "$ENABLE_METADATA_QUERY" == "true" ]; then #linkis-ps-data-source-manager SERVER_NAME="ps-data-source-manager" SERVER_IP=$DATASOURCE_MANAGER_INSTALL_IP startApp
#linkis-ps-metadataquery SERVER_NAME="ps-metadataquery" SERVER_IP=$METADATA_QUERY_INSTALL_IP startAppfi
#linkis-ps-csSERVER_NAME="ps-cs"SERVER_IP=$CS_INSTALL_IPcheckServer
if [ "$ENABLE_METADATA_QUERY" == "true" ]; then #linkis-ps-data-source-manager SERVER_NAME="ps-data-source-manager" SERVER_IP=$DATASOURCE_MANAGER_INSTALL_IP checkServer
#linkis-ps-metadataquery SERVER_NAME="ps-metadataquery" SERVER_IP=$METADATA_QUERY_INSTALL_IP checkServerfi
#Service stop script remove the following part #linkis-ps-cs SERVER_NAME="ps-cs" SERVER_IP=$CS_INSTALL_IP stopApp
if [ "$ENABLE_METADATA_QUERY" == "true" ]; then #linkis-ps-data-source-manager SERVER_NAME ="ps-data-source-manager" SERVER_IP=$DATASOURCE_MANAGER_INSTALL_IP stopApp
#linkis-ps-metadataquery SERVER_NAME="ps-metadataquery" SERVER_IP=$METADATA_QUERY_INSTALL_IP stopApp fi
For more details on service merge changes, see: https://github .com/apache/incubator-linkis/pull/2927/files

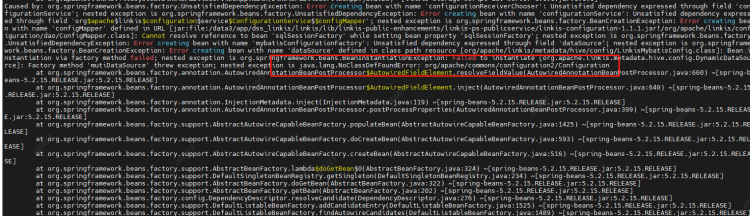
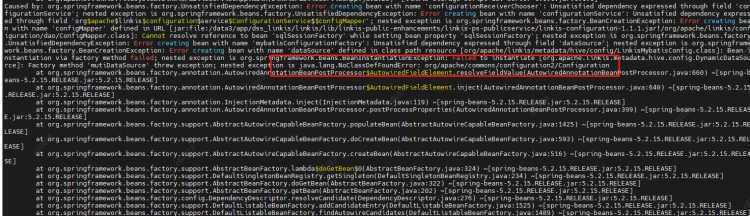
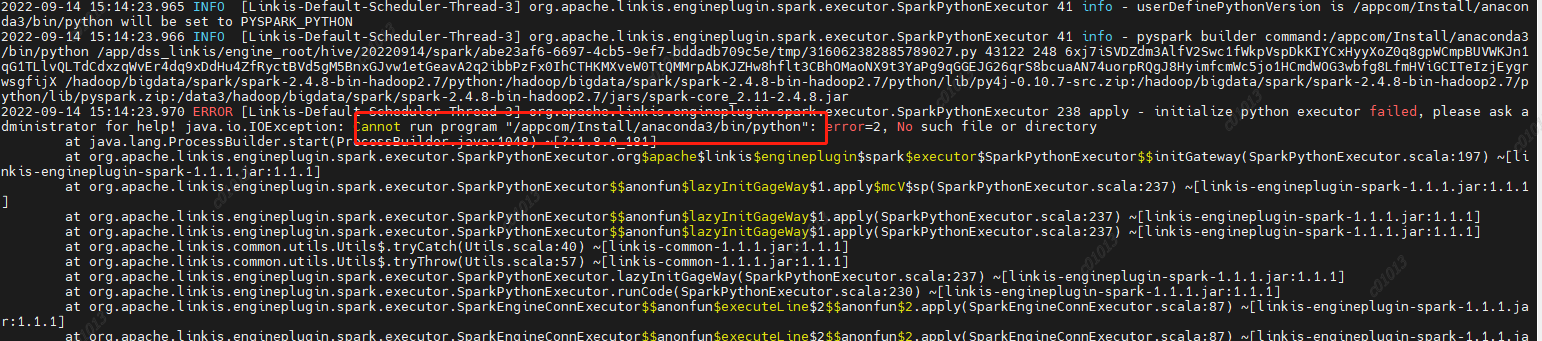
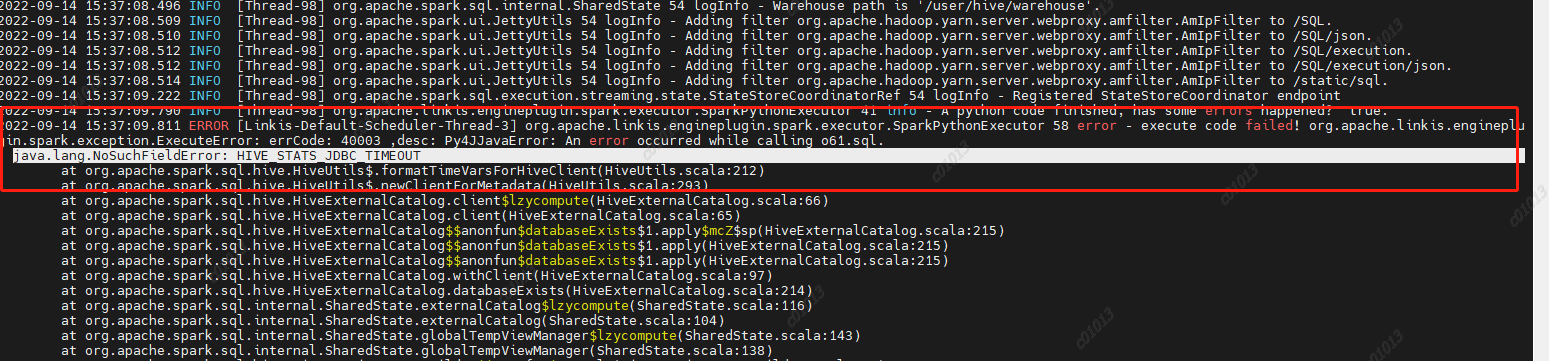
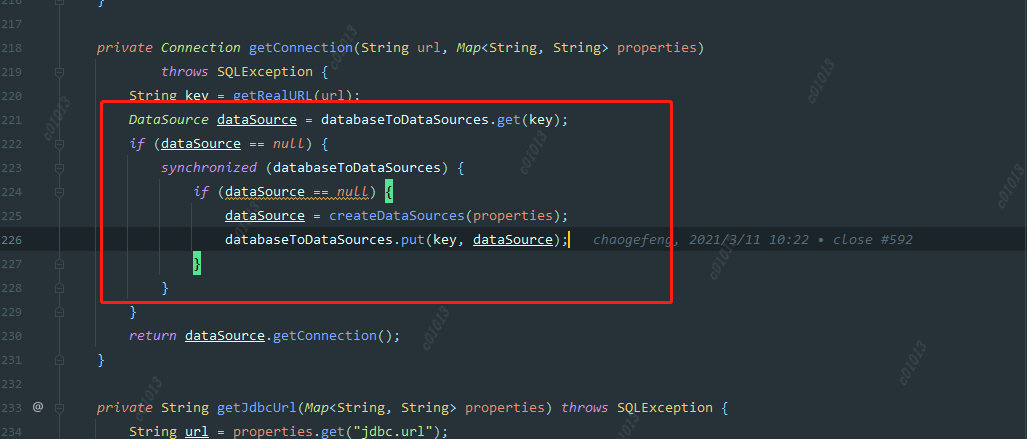

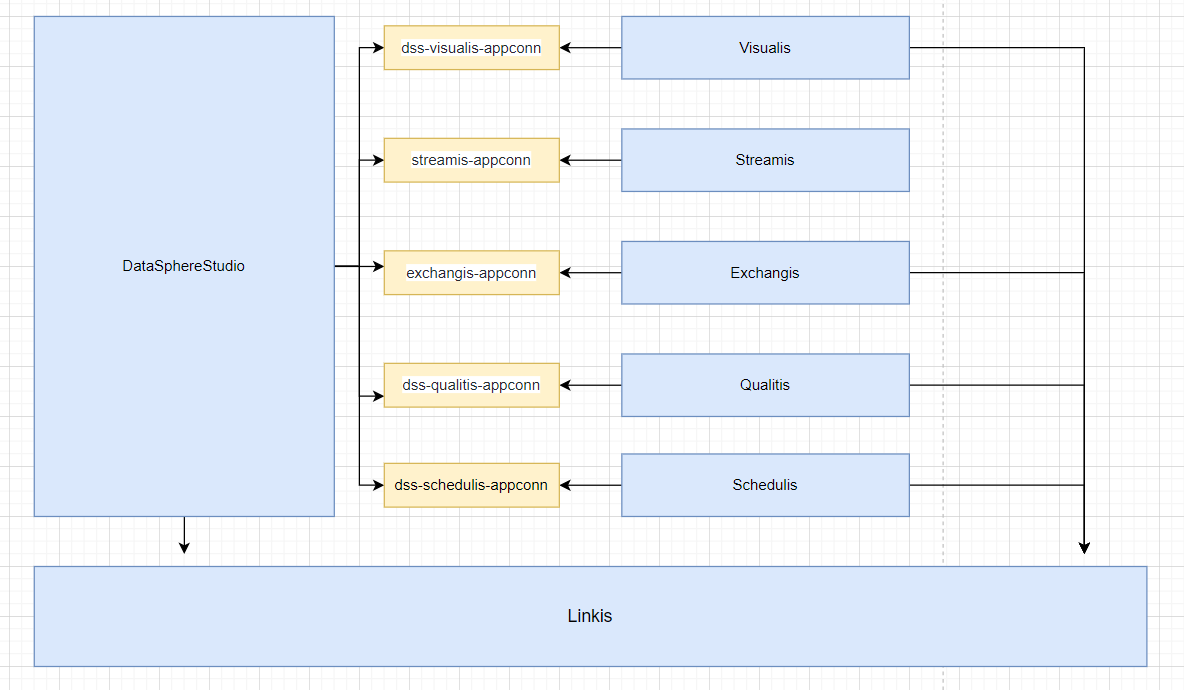
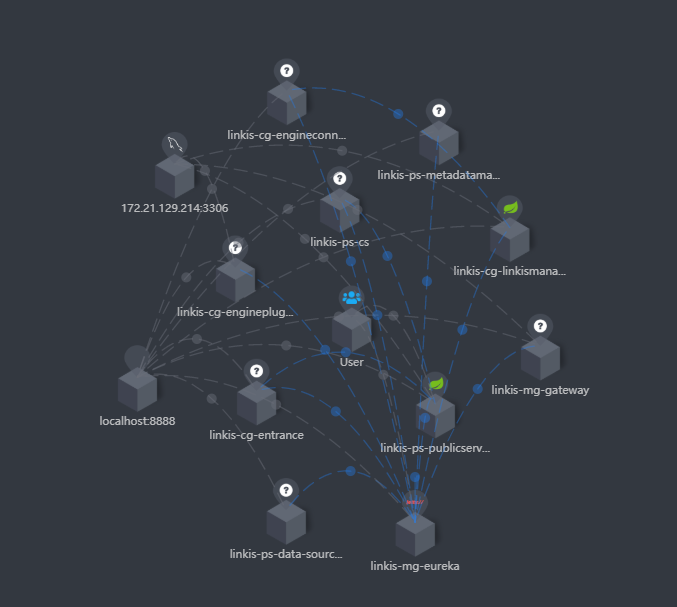 At the same time, you can also clearly see the call link in the trace, as shown in the following figure, which is also convenient for you to locate the error log file of the specific service
At the same time, you can also clearly see the call link in the trace, as shown in the following figure, which is also convenient for you to locate the error log file of the specific service


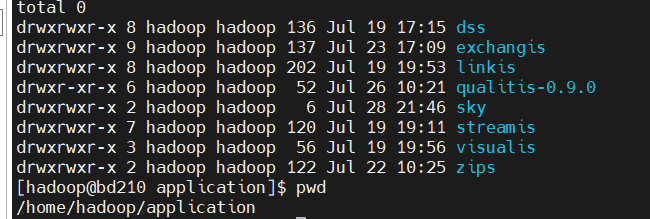

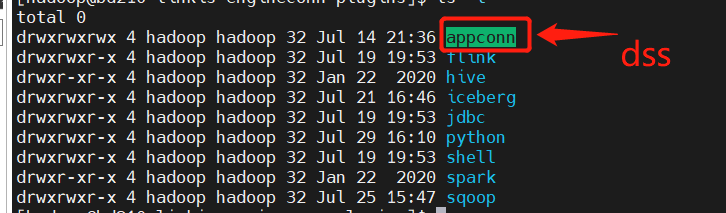
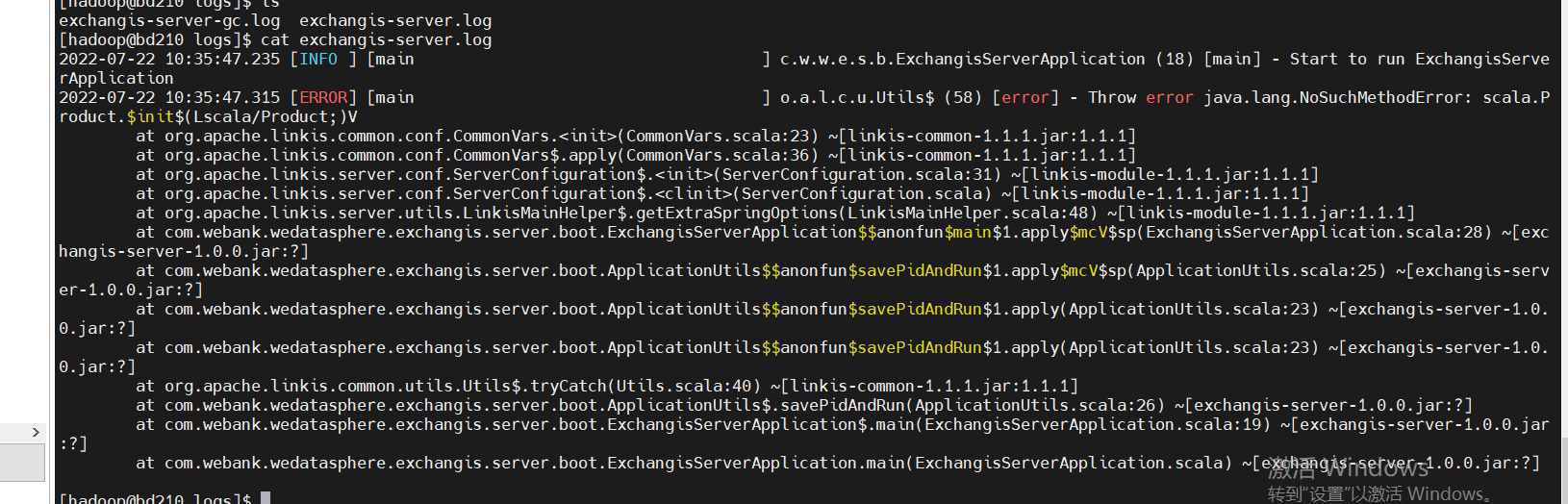
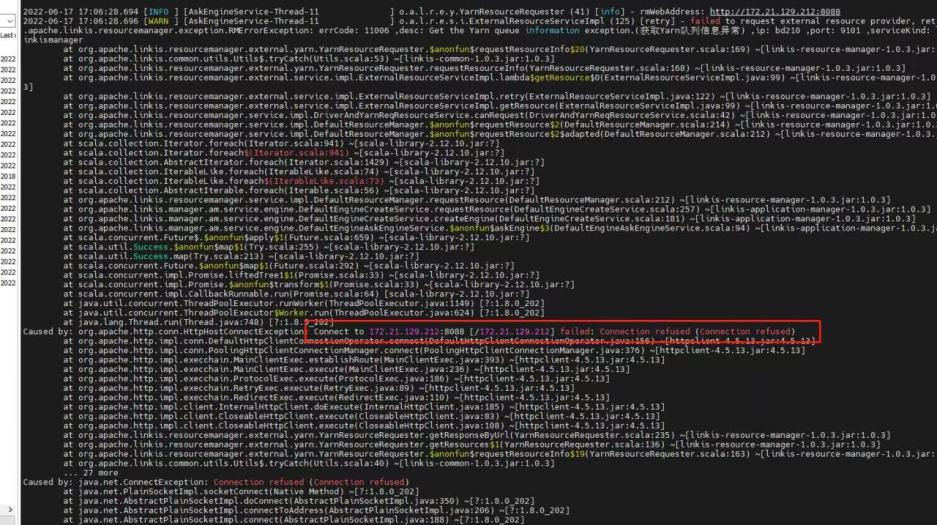
 For example, for qualitis, the following IP and host ports are determined according to their specific use
For example, for qualitis, the following IP and host ports are determined according to their specific use