快速部署
温馨提示:如果您想体验LINKIS全家桶:DSS + Linkis + Qualitis + Visualis + Azkaban,请访问DSS一键部署#
1 确定安装环境#
Linkis根据安装的难易程度,提供了以下三种安装环境的准备方式,其区别如下:
精简版:
最少环境依赖,单节点安装模式,只包含Python引擎,只需要用户Linux环境支持Python即可。
请注意:精简版只允许用户提交Python脚本。
简单版:
依赖Python、Hadoop和Hive,分布式安装模式,包含Python引擎和Hive引擎,需要用户的Linux环境先安装好了Hadoop和Hive。
简单版允许用户提交HiveQL和Python脚本。
标准版
依赖Python、Hadoop、Hive和Spark,分布式安装模式,包含Python引擎、Hive引擎和Spark引擎,需要用户的Linux环境先安装好了Hadoop、Hive和Spark,Linkis的机器依赖集群的hadoop/hive/spark的配置文件,并不需要和DataNode和NameNode机器部署在一起,在单独的Client机器上面部署即可。
标准版允许用户提交Spark脚本(包含SparkSQL、Pyspark和Scala)、HiveQL和Python脚本。
请注意:安装标准版需要机器内存在10G以上 如果机器内存不够,需要添加或者修改环境变量:export SERVER_HEAP_SIZE="512M"
2 精简版Linkis环境准备#
2.1. 基础软件安装#
下面的软件必装:
- MySQL (5.5+),如何安装MySQL
- JDK (1.8.0_141以上),如何安装JDK
- Python(2.x和3.x都支持),如何安装Python
2.2 创建用户#
例如: 部署用户是hadoop账号
- 在部署机器上创建部署用户,用于安装
sudo useradd hadoop - 因为Linkis的服务是以 sudo -u ${linux-user} 方式来切换引擎,从而执行作业,所以部署用户需要有 sudo 权限,而且是免密的。
vi /etc/sudoers hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL- 如果您的Python想拥有画图功能,则还需在安装节点,安装画图模块。命令如下:
python -m pip install matplotlib2.3 安装包准备#
从Linkis已发布的release中(点击这里进入下载页面),下载最新安装包。
先解压安装包到安装目录,并对解压后的文件进行配置修改。
tar -xvf wedatasphere-linkis-x.x.x-dist.tar.gz(1)修改基础配置
vi conf/config.sh SSH_PORT=22 #指定SSH端口,如果单机版本安装可以不配置 deployUser=hadoop #指定部署用户 LINKIS_HOME=/appcom/Install/Linkis # 指定安装目录 WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop # 指定用户根目录,一般用于存储用户的脚本文件和日志文件等,是用户的工作空间。 RESULT_SET_ROOT_PATH=file:///tmp/linkis # 结果集文件路径,用于存储Job的结果集文件 #HDFS_USER_ROOT_PATH=hdfs:///tmp/linkis #精简版安装需要注释该参数(2)修改数据库配置
vi conf/db.sh # 设置数据库的连接信息 # 包括IP地址、数据库名称、用户名、端口 # 主要用于存储用户的自定义变量、配置参数、UDF和小函数,以及提供JobHistory的底层存储 MYSQL_HOST= MYSQL_PORT= MYSQL_DB= MYSQL_USER= MYSQL_PASSWORD=环境准备完毕,点我进入 5-安装部署
3 简单版Linkis环境准备#
3.1 基础软件安装#
下面的软件必装:
- MySQL (5.5+),如何安装MySQL
- JDK (1.8.0_141以上),如何安装JDK
- Python(2.x和3.x都支持),如何安装Python
- Hadoop(社区版和CDH3.0以下版本都支持)
- Hive(1.2.1,2.0和2.0以上版本,可能存在兼容性问题)
3.2 创建用户#
例如: 部署用户是hadoop账号
- 在所有需要部署的机器上创建部署用户,用于安装
sudo useradd hadoop- 因为Linkis的服务是以 sudo -u ${linux-user} 方式来切换引擎,从而执行作业,所以部署用户需要有 sudo 权限,而且是免密的。
vi /etc/sudoers hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL - 在每台安装节点设置如下的全局环境变量,以便Linkis能正常使用Hadoop和Hive
修改安装用户的.bash_rc,命令如下:
vim /home/hadoop/.bash_rc下方为环境变量示例: #JDK export JAVA_HOME=/nemo/jdk1.8.0_141 #HADOOP export HADOOP_HOME=/appcom/Install/hadoop export HADOOP_CONF_DIR=/appcom/config/hadoop-config #Hive export HIVE_HOME=/appcom/Install/hive export HIVE_CONF_DIR=/appcom/config/hive-config3.3 SSH免密配置(分布式模式必须)#
如果您的Linkis都部署在同一台服务器上, 本步骤可以跳过。
如果您的Linkis部署在多台服务器上,那么您还需要为这些服务器配置ssh免密登陆。
3.4 安装包准备#
从Linkis已发布的release中(点击这里进入下载页面),下载最新安装包。
先解压安装包到安装目录,并对解压后的文件进行配置修改。
tar -xvf wedatasphere-linkis-x.x.x-dist.tar.gz(1)修改基础配置
vi /conf/config.sh deployUser=hadoop #指定部署用户 LINKIS_HOME=/appcom/Install/Linkis # 指定安装目录 WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop # 指定用户根目录,一般用于存储用户的脚本文件和日志文件等,是用户的工作空间。 HDFS_USER_ROOT_PATH=hdfs:///tmp/linkis # 指定用户的HDFS根目录,一般用于存储Job的结果集文件
# 如果您想配合Scriptis一起使用,CDH版的Hive,还需要配置如下参数(社区版Hive可忽略该配置) HIVE_META_URL=jdbc://... # HiveMeta元数据库的URL HIVE_META_USER= # HiveMeta元数据库的用户 HIVE_META_PASSWORD= # HiveMeta元数据库的密码
# 配置hadoop/hive/spark的配置目录 HADOOP_CONF_DIR=/appcom/config/hadoop-config #hadoop的conf目录 HIVE_CONF_DIR=/appcom/config/hive-config #hive的conf目录(2)修改数据库配置
vi conf/db.sh
# 设置数据库的连接信息 # 包括IP地址、数据库名称、用户名、端口 # 主要用于存储用户的自定义变量、配置参数、UDF和小函数,以及提供JobHistory的底层存储 MYSQL_HOST= MYSQL_PORT= MYSQL_DB= MYSQL_USER= MYSQL_PASSWORD=环境准备完毕,点我进入 5-安装部署
4 标准版Linkis环境准备#
4.1 基础软件安装#
下面的软件必装:
- MySQL (5.5+),如何安装MySQL
- JDK (1.8.0_141以上),如何安装JDK
- Python(2.x和3.x都支持),如何安装Python
- Hadoop(社区版和CDH3.0以下版本都支持)
- Hive(1.2.1,2.0和2.0以上版本,可能存在兼容性问题)
- Spark(Linkis release0.7.0开始,支持Spark2.0以上所有版本)
4.2 创建用户#
例如: 部署用户是hadoop账号
- 在所有需要部署的机器上创建部署用户,用于安装
sudo useradd hadoop- 因为Linkis的服务是以 sudo -u ${linux-user} 方式来切换引擎,从而执行作业,所以部署用户需要有 sudo 权限,而且是免密的。
vi /etc/sudoers hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL在每台安装节点设置如下的全局环境变量,以便Linkis能正常使用Hadoop、Hive和Spark
修改安装用户的.bash_rc,命令如下:
vim /home/hadoop/.bash_rc下方为环境变量示例: #JDK export JAVA_HOME=/nemo/jdk1.8.0_141 #HADOOP export HADOOP_HOME=/appcom/Install/hadoop export HADOOP_CONF_DIR=/appcom/config/hadoop-config #Hive export HIVE_HOME=/appcom/Install/hive export HIVE_CONF_DIR=/appcom/config/hive-config #Spark export SPARK_HOME=/appcom/Install/spark export SPARK_CONF_DIR=/appcom/config/spark-config/spark-submit export PYSPARK_ALLOW_INSECURE_GATEWAY=1 # Pyspark必须加的参数- 如果您的Pyspark想拥有画图功能,则还需在所有安装节点,安装画图模块。命令如下:
python -m pip install matplotlib4.3 SSH免密配置(分布式模式必须)#
如果您的Linkis都部署在同一台服务器上, 本步骤可以跳过。
如果您的Linkis部署在多台服务器上,那么您还需要为这些服务器配置ssh免密登陆。
4.4 安装包准备#
从Linkis已发布的release中(点击这里进入下载页面),下载最新安装包。
先解压安装包到安装目录,并对解压后的文件进行配置修改。
tar -xvf wedatasphere-linkis-x.x.0-dist.tar.gz(1)修改基础配置
vi conf/config.sh SSH_PORT=22 #指定SSH端口,如果单机版本安装可以不配置 deployUser=hadoop #指定部署用户 LINKIS_HOME=/appcom/Install/Linkis # 指定安装目录 WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop # 指定用户根目录,一般用于存储用户的脚本文件和日志文件等,是用户的工作空间。 HDFS_USER_ROOT_PATH=hdfs:///tmp/linkis # 指定用户的HDFS根目录,一般用于存储Job的结果集文件
# 如果您想配合Scriptis一起使用,CDH版的Hive,还需要配置如下参数(社区版Hive可忽略该配置) HIVE_META_URL=jdbc://... # HiveMeta元数据库的URL HIVE_META_USER= # HiveMeta元数据库的用户 HIVE_META_PASSWORD= # HiveMeta元数据库的密码 # 配置hadoop/hive/spark的配置目录 HADOOP_CONF_DIR=/appcom/config/hadoop-config #hadoop的conf目录 HIVE_CONF_DIR=/appcom/config/hive-config #hive的conf目录 SPARK_CONF_DIR=/appcom/config/spark-config #spark的conf目录(2)修改数据库配置
vi conf/db.sh
# 设置数据库的连接信息 # 包括IP地址、数据库名称、用户名、端口 # 主要用于存储用户的自定义变量、配置参数、UDF和小函数,以及提供JobHistory的底层存储 MYSQL_HOST= MYSQL_PORT= MYSQL_DB= MYSQL_USER= MYSQL_PASSWORD=5 安装部署#
5.1 执行安装脚本:#
sh bin/install.sh5.2 安装步骤#
- install.sh脚本会询问您安装模式。
安装模式就是精简模式、简单模式或标准模式,请根据您准备的环境情况,选择合适的安装模式。
- install.sh脚本会询问您是否需要初始化数据库并导入元数据。
因为担心用户重复执行install.sh脚本,把数据库中的用户数据清空,所以在install.sh执行时,会询问用户是否需要初始化数据库并导入元数据。
第一次安装必须选是。
5.3 是否安装成功:#
通过查看控制台打印的日志信息查看是否安装成功。
如果有错误信息,可以查看具体报错原因。
5.4 快速启动Linkis#
(1)、启动服务:#
在安装目录执行以下命令,启动所有服务:
./bin/start-all.sh > start.log 2>start_error.log(2)、查看是否启动成功#
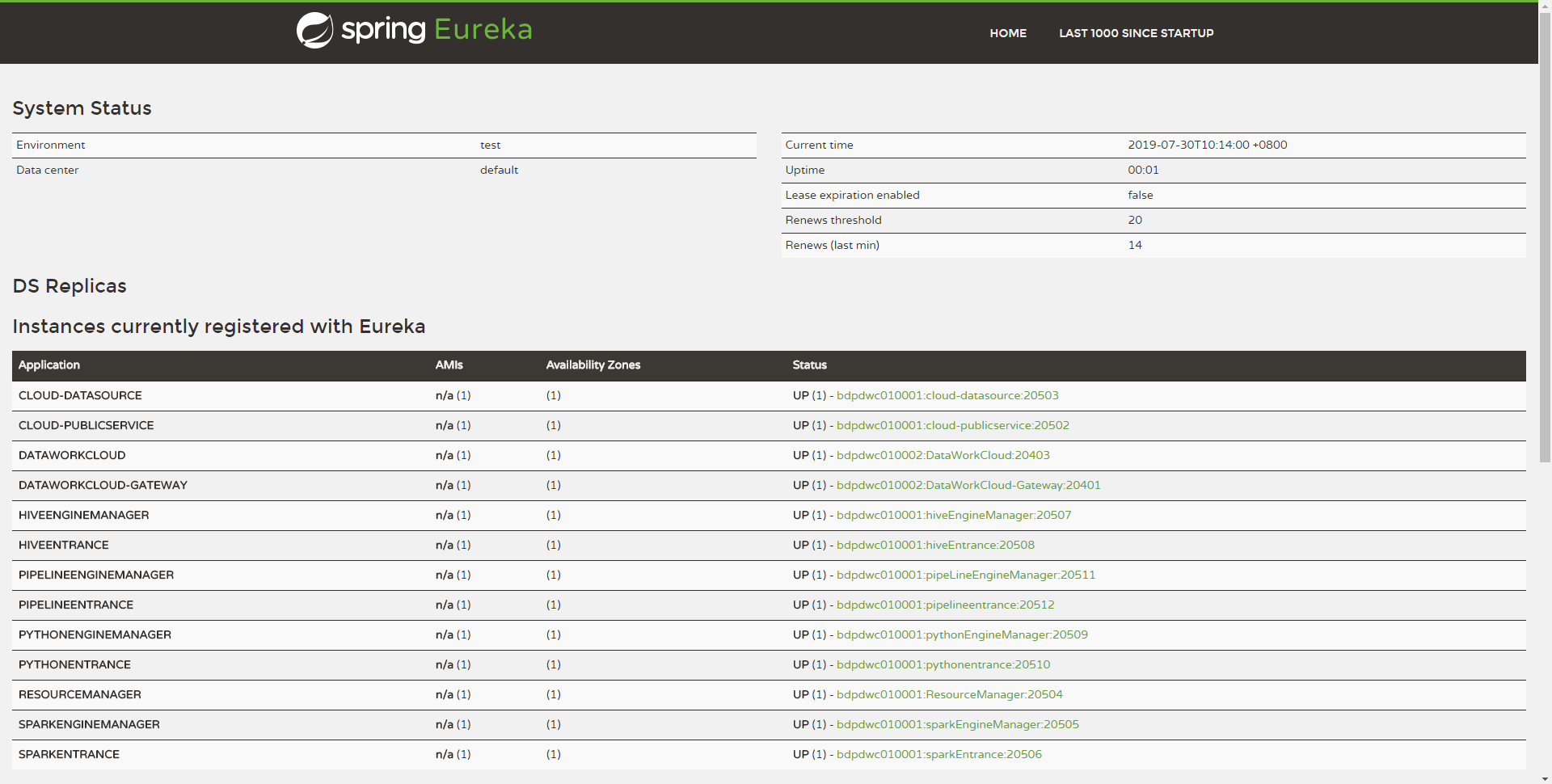
可以在Eureka界面查看服务启动成功情况,查看方法:
使用http://${EUREKA_INSTALL_IP}:${EUREKA_PORT}, 在浏览器中打开,查看服务是否注册成功。
如果您没有在config.sh指定EUREKA_INSTALL_IP和EUREKA_INSTALL_IP,则HTTP地址为:http://127.0.0.1:20303
如下图,如您的Eureka主页出现以下微服务,则表示服务都启动成功,可以正常对外提供服务了:
注意: 其中标红的为DSS服务,其余为Linkis服务,如果只使用linkis可以忽略标红的部分
6. 快速使用Linkis#
6.1 概述#
Linkis为用户提供了Java客户端的实现,用户可以使用UJESClient对Linkis后台服务实现快速访问。
6.2 快速运行#
我们在ujes/client/src/test模块下,提供了UJESClient的两个测试类:
com.webank.wedatasphere.linkis.ujes.client.UJESClientImplTestJ # 基于Java实现的测试类 com.webank.wedatasphere.linkis.ujes.client.UJESClientImplTest # 基于Scala实现的测试类 如果您clone了Linkis的源代码,可以直接运行这两个测试类。
6.3 快速实现#
下面具体介绍如何快速实现一次对Linkis的代码提交执行。
6.3.1 maven依赖#
<dependency> <groupId>com.webank.wedatasphere.Linkis</groupId> <artifactId>Linkis-ujes-client</artifactId> <version>0.11.0</version></dependency>6.3.2 参考实现#
- JAVA
package com.webank.bdp.dataworkcloud.ujes.client;
import com.webank.wedatasphere.Linkis.common.utils.Utils;import com.webank.wedatasphere.Linkis.httpclient.dws.authentication.StaticAuthenticationStrategy;import com.webank.wedatasphere.Linkis.httpclient.dws.config.DWSClientConfig;import com.webank.wedatasphere.Linkis.httpclient.dws.config.DWSClientConfigBuilder;import com.webank.wedatasphere.Linkis.ujes.client.UJESClient;import com.webank.wedatasphere.Linkis.ujes.client.UJESClientImpl;import com.webank.wedatasphere.Linkis.ujes.client.request.JobExecuteAction;import com.webank.wedatasphere.Linkis.ujes.client.request.ResultSetAction;import com.webank.wedatasphere.Linkis.ujes.client.response.JobExecuteResult;import com.webank.wedatasphere.Linkis.ujes.client.response.JobInfoResult;import com.webank.wedatasphere.Linkis.ujes.client.response.JobProgressResult;import com.webank.wedatasphere.Linkis.ujes.client.response.JobStatusResult;import org.apache.commons.io.IOUtils;
import java.util.concurrent.TimeUnit;
public class UJESClientImplTestJ{ public static void main(String[] args){ // 1. 配置DWSClientBuilder,通过DWSClientBuilder获取一个DWSClientConfig DWSClientConfig clientConfig = ((DWSClientConfigBuilder) (DWSClientConfigBuilder.newBuilder() .addUJESServerUrl("http://${ip}:${port}") //指定ServerUrl,Linkis服务器端网关的地址,如http://{ip}:{port} .connectionTimeout(30000) //connectionTimeOut 客户端连接超时时间 .discoveryEnabled(true).discoveryFrequency(1, TimeUnit.MINUTES) //是否启用注册发现,如果启用,会自动发现新启动的Gateway .loadbalancerEnabled(true) // 是否启用负载均衡,如果不启用注册发现,则负载均衡没有意义 .maxConnectionSize(5) //指定最大连接数,即最大并发数 .retryEnabled(false).readTimeout(30000) //执行失败,是否允许重试 .setAuthenticationStrategy(new StaticAuthenticationStrategy()) //AuthenticationStrategy Linkis认证方式 .setAuthTokenKey("johnnwang").setAuthTokenValue("Abcd1234"))) //认证key,一般为用户名; 认证value,一般为用户名对应的密码 .setDWSVersion("v1").build(); //Linkis后台协议的版本,当前版本为v1 // 2. 通过DWSClientConfig获取一个UJESClient UJESClient client = new UJESClientImpl(clientConfig);
// 3. 开始执行代码 JobExecuteResult jobExecuteResult = client.execute(JobExecuteAction.builder() .setCreator("LinkisClient-Test") //creator,请求Linkis的客户端的系统名,用于做系统级隔离 .addExecuteCode("show tables") //ExecutionCode 请求执行的代码 .setEngineType(JobExecuteAction.EngineType$.MODULE$.HIVE()) // 希望请求的Linkis的执行引擎类型,如Spark hive等 .setUser("johnnwang") //User,请求用户;用于做用户级多租户隔离 .build()); System.out.println("execId: " + jobExecuteResult.getExecID() + ", taskId: " + jobExecuteResult.taskID()); // 4. 获取脚本的执行状态 JobStatusResult status = client.status(jobExecuteResult); while(!status.isCompleted()) { // 5. 获取脚本的执行进度 JobProgressResult progress = client.progress(jobExecuteResult); Utils.sleepQuietly(500); status = client.status(jobExecuteResult); } // 6. 获取脚本的Job信息 JobInfoResult jobInfo = client.getJobInfo(jobExecuteResult); // 7. 获取结果集列表(如果用户一次提交多个SQL,会产生多个结果集) String resultSet = jobInfo.getResultSetList(client)[0]; // 8. 通过一个结果集信息,获取具体的结果集 Object fileContents = client.resultSet(ResultSetAction.builder().setPath(resultSet).setUser(jobExecuteResult.getUser()).build()).getFileContent(); System.out.println("fileContents: " + fileContents); IOUtils.closeQuietly(client); }}- SCALA
import java.util.concurrent.TimeUnit
import com.webank.wedatasphere.Linkis.common.utils.Utilsimport com.webank.wedatasphere.Linkis.httpclient.dws.authentication.StaticAuthenticationStrategyimport com.webank.wedatasphere.Linkis.httpclient.dws.config.DWSClientConfigBuilderimport com.webank.wedatasphere.Linkis.ujes.client.request.JobExecuteAction.EngineTypeimport com.webank.wedatasphere.Linkis.ujes.client.request.{JobExecuteAction, ResultSetAction}import org.apache.commons.io.IOUtils
object UJESClientImplTest extends App {
// 1. 配置DWSClientBuilder,通过DWSClientBuilder获取一个DWSClientConfig val clientConfig = DWSClientConfigBuilder.newBuilder() .addUJESServerUrl("http://${ip}:${port}") //指定ServerUrl,Linkis服务器端网关的地址,如http://{ip}:{port} .connectionTimeout(30000) //connectionTimeOut 客户端连接超时时间 .discoveryEnabled(true).discoveryFrequency(1, TimeUnit.MINUTES) //是否启用注册发现,如果启用,会自动发现新启动的Gateway .loadbalancerEnabled(true) // 是否启用负载均衡,如果不启用注册发现,则负载均衡没有意义 .maxConnectionSize(5) //指定最大连接数,即最大并发数 .retryEnabled(false).readTimeout(30000) //执行失败,是否允许重试 .setAuthenticationStrategy(new StaticAuthenticationStrategy()) //AuthenticationStrategy Linkis认证方式 .setAuthTokenKey("${username}").setAuthTokenValue("${password}") //认证key,一般为用户名; 认证value,一般为用户名对应的密码 .setDWSVersion("v1").build() //Linkis后台协议的版本,当前版本为v1 // 2. 通过DWSClientConfig获取一个UJESClient val client = UJESClient(clientConfig)
// 3. 开始执行代码 val jobExecuteResult = client.execute(JobExecuteAction.builder() .setCreator("LinkisClient-Test") //creator,请求Linkis的客户端的系统名,用于做系统级隔离 .addExecuteCode("show tables") //ExecutionCode 请求执行的代码 .setEngineType(EngineType.SPARK) // 希望请求的Linkis的执行引擎类型,如Spark hive等 .setUser("${username}").build()) //User,请求用户;用于做用户级多租户隔离 println("execId: " + jobExecuteResult.getExecID + ", taskId: " + jobExecuteResult.taskID) // 4. 获取脚本的执行状态 var status = client.status(jobExecuteResult) while(!status.isCompleted) { // 5. 获取脚本的执行进度 val progress = client.progress(jobExecuteResult) val progressInfo = if(progress.getProgressInfo != null) progress.getProgressInfo.toList else List.empty println("progress: " + progress.getProgress + ", progressInfo: " + progressInfo) Utils.sleepQuietly(500) status = client.status(jobExecuteResult) } // 6. 获取脚本的Job信息 val jobInfo = client.getJobInfo(jobExecuteResult) // 7. 获取结果集列表(如果用户一次提交多个SQL,会产生多个结果集) val resultSet = jobInfo.getResultSetList(client).head // 8. 通过一个结果集信息,获取具体的结果集 val fileContents = client.resultSet(ResultSetAction.builder().setPath(resultSet).setUser(jobExecuteResult.getUser).build()).getFileContent println("fileContents: " + fileContents) IOUtils.closeQuietly(client)}